先强调一点,到现在没有任何技术是完全旁路了CPU,控制面上只是尽量让CPU少参与,而不是完全不参与。
GPUDirect
GPUDirect并不是一门很新的技术了,这个概念由Nvidia在2012年Kepler这一代GPU微架构率先提出来。
结合RDMA技术,它允许单机或者网络中的GPU可以互相交换数据,而不用经过CPU/系统内存。
结合PCIe的Peer-to-Peer技术,它可以直接访问同一个PCIe rootport下的其它设备,而不用绕一圈到cpu或者系统内存。
更形象的看,可以看看下面两个图,做个对比,就更加直观了:


再深入之前,先了解下P2P技术的几个阶段:
MLX的roadmap:

Nvidia的roadmap:

看懂了roadmap,才能理解nvidia背后收购MLX的战略意义。
有了P2P之后,作为设备厂商的Nvidia一直想着怎么旁路CPU,抢占intel的市场,推出了各种direct技术。
最后发展成nvidia magnum io。后文会围绕这些技术展开。

地址的问题
GPUDirect要解决的第一个问题,是地址的问题,要保证设备之间地址的一致性,或者说要让其它设备认识GPU的地址。
在linux kernel中,普通的设备驱动的大致流程,都是用户态把数据读/写到用户态VA,内核把VA转换成PA,
驱动程序在把PA转换成IOVA(或者说是DMA地址)。中间过程可能需要pin住或者unpin用户态内存,常见处理都是用get_user_pages和put_page等函数。
那现在要旁路CPU,而GPU中的代码执行的都是GPU的地址,这样就要求和其它设备和GPU是一个地址。
前文已经说过,GPU的内存是通过PCIe BAR空间呈现给CPU的,同理,在GPUDirect技术下,这个内存也要让其它
设备看看到。
GPUDirect with RDMA
常规RDMA编程
再解释GPUDirect RDMA之前,先回顾下普通的RDMA程序是怎么写的。一般使用libibverbs这个库提供的API使用RDMA技术,基本分为以下几步:
* Create an Infiniband context (struct ibv_context* ibv_open_device())
* Create a protection domain (struct ibv_pd* ibv_alloc_pd())
* Create a completion queue (struct ibv_cq* ibv_create_cq())
* Create a queue pair (struct ibv_qp* ibv_create_qp())
* Exchange identifier information to establish connection
* Change the queue pair state (ibv_modify_qp()): change the state of the queue pair from RESET to INIT, RTR (Ready to Receive), and finally RTS (Ready to Send) 5
* Register a memory region (ibv_reg_mr())
* Exchange memory region information to handle operations
* Perform data communication
其中最关键一步是register a memory region,用的时候通常是下面这么用,用户需要指定buffer的地址和大小:
struct ibv_mr* registerMemoryRegion(struct ibv_pd* pd, void* buffer, size_t size) {
return ibv_reg_mr(pd, buffer, size, IBV_ACCESS_LOCAL_WRITE | IBV_ACCESS_REMOTE_READ | IBV_ACCESS_REMOTE_WRITE);
}
GPUDirect RDMA编程
GPUDirect RDMA的发展也分为几个阶段,在初期只是offload数据面,控制面还是在CPU,
后面又尽可能把控制面也给GPU,但是还是有小部分处理必须在CPU。
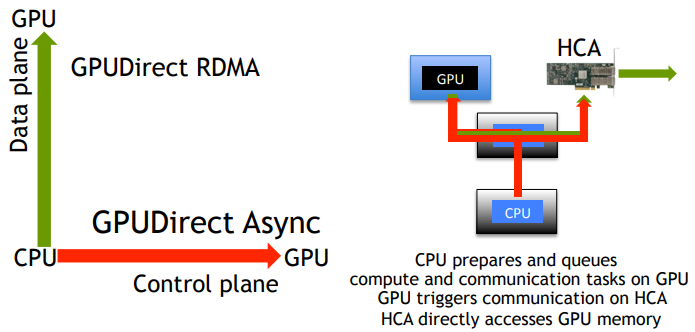
GPUDirect RDMA
先看看Nvidia GPUDirect RDMA技术解决的问题:怎么让一个PCIe RP下的RDMA网卡可以直接访问GPU的内存,而避免把数据拷贝多次?

由于GPU内存被RDMA网卡可见,所以写代码的时候,可以少申请一次malloc和memcpy。
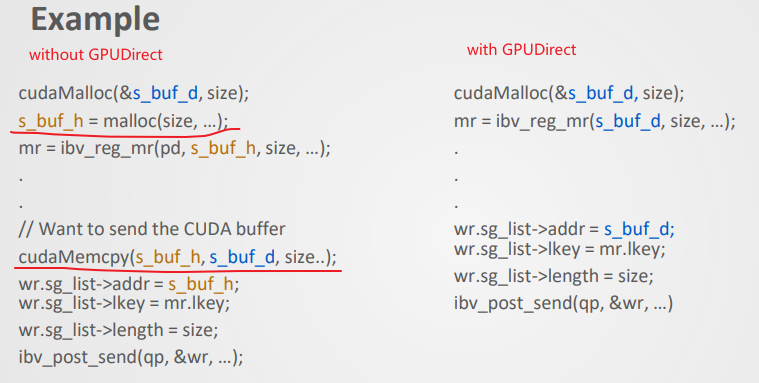
上面ibv_reg_mr注册内存的时候,居然允许注册GPU(peer to peer设备)的内存。
为了做到这一步,MLX做了几下几步:
- 引入
io_peer_mem这个ko模块,先把peer设备的内存暴露出来,并把peer设备作为client通过ib_register_peer_memory_clent注册到RDMA子系统中 io_peer_mem主要实现三个回调函数:- acquire: 判断一个虚拟地址是否属于该peer设备
- get_pages:获取这个memory region的物理地址
- dma_map:获取这个memory region的iova地址
具体流程如下:
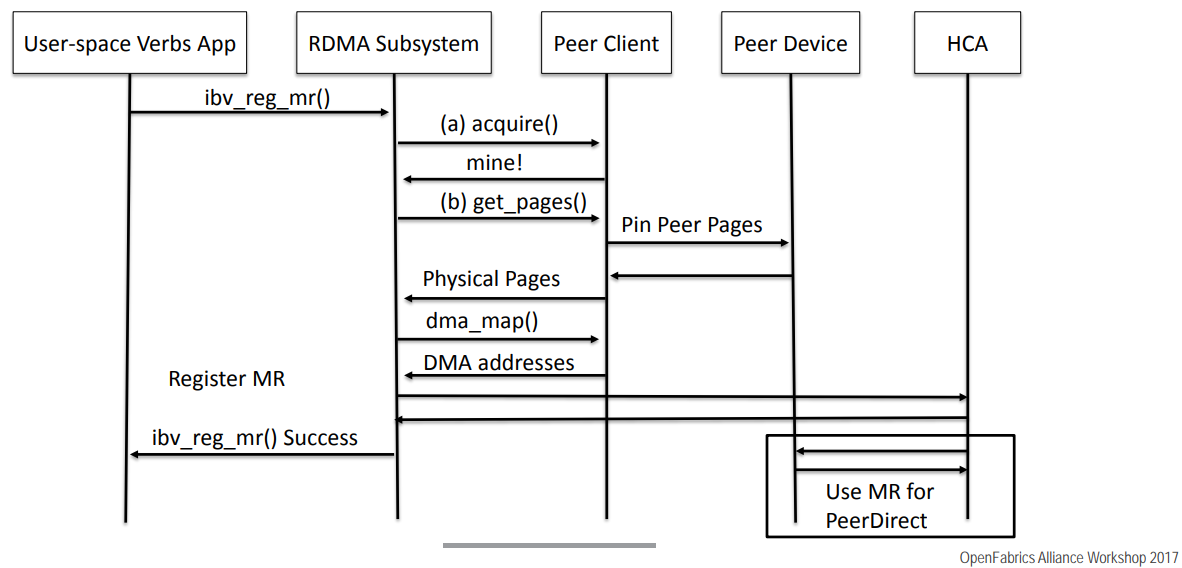
到这里,已经可以让RDMA网卡访问GPU的内存了,为了让GPU和网卡并行起来,CPU仍然扮演了厚重的调度角色,而且GPU空转时间比较长。

有人想把控制面也offload一部分,于是乎GPUDirect Async概念被提了出来。
GPUDirect Async
整体的逻辑如下:

依赖的软件如下:

整体软件栈:

具体的用户态代码参考libgdsync
Nvidia NCCL
后来Nvidia基于上面互联通信这些技术,又提出了NCCL概念。

GPUDirect Storage
沿着RDMA的思路,在存储上,GPUDirect Storage概念也被提了出来。
和传统存储相比,仍然是旁路CPU,具体如下:

先还是回顾下linux kernel中普通存储的软件堆栈:

Nvidia在虚拟文件系统VFS之上做了一个nvidia-fs.ko,
负责把GPU的内存(GPU的部分BAR空间)给到文件系统。整个软件栈如下:

更具体一点:

用户态的代码写的时候,就变成下面这样了
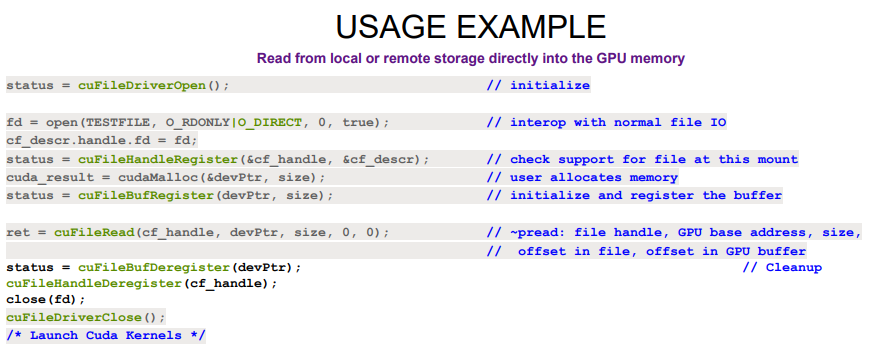
其中cudaMalloc/cuFileBufRegister会从GPU内存分配,并调用nvidia-fs.ko做映射,得到一个va和gpu pa/dma、cpu pa的映射,
后面再调用cuFileRead/cuFileWrite的时候把这个va传递给虚拟文件系统VFS,并通过kernel的call_write_iter/call_read_iter
函数进行文件读写,之后底层sas控制器或者nvme控制器的驱动通过dma_map相关函数把这个va又转换成具体的pa,把内容读或者
写到这块地址中,具体流程如下:
nvfs_open
nvfs_blk_register_dma_ops
register nvfs_dma_rw_ops
cuFileRead/cuFileWrite
nvfs_ioctl
nvfs_start_io_op
nvfs_direct_io
call_write_iter/call_read_iter
blk_mq_ops.queue_rq
nvme_queue_rq
nvme_map_data
dma_map_bvec
call nvfs register dma callback
具体可以参考代码: https://github.com/NVIDIA/gds-nvidia-fs/blob/master/src/nvfs-core.c#L981

另外nvdia-fs.ko也可以和网络、RDMA结合在一起,配合用户态的cuFile RDMA访问网络上的存储设备。
cufile的库并没有开源,具体的实现还看不到,主要做了以下事情:


Nvidia Magnum IO
有了上面这些网络加速、IO加速技术之后,Nvidia更进一步提出了Magnum IO技术,把这些都打包在了一起。

参考
- Developing a Linux Kernel Module using GPUDirect RDMA
- ParallelComputingSpring2015
- GPU Direct IO with HDF5
- gdrcopy
- GPUDirect RDMA and Green Multi-GPU Architectures
- Asynchronous Peer-to-Peer Device Communication
- Advancing Communication Technologies and System Architecture to Maxime Performance and Scalability of GPU Accelerated Systems
- Introduction to Programming Infiniband RDMA
- OFVWG:GPUDirect and PeerDirect
- RDMA over ML/DL and Big Data Frameworks
- Accelerating IO in the Modern Data Center: Magnum IO Architecture
- GPU Direct IO with HDF5
- OFED and GPUDirect
- GPUrdma: GPU-side library for high performance networking from GPU kernels
- GPUDIRECT STORAGE:A DIRECT GPU-STORAGE DATA PATH
- NVIDIA Magnum IO GPUDirect Storage Overview Guide
- NVIDIA GPU Direct Storage with IBM Spectrum Scale
- NVIDIA Magnum IO GPUDirect Storage design guide
- DRM 驱动 mmap 详解:(一)预备知识
- GPU Direct Storage

