背景知识
内存分配 - linux kernel lazy memory allocation
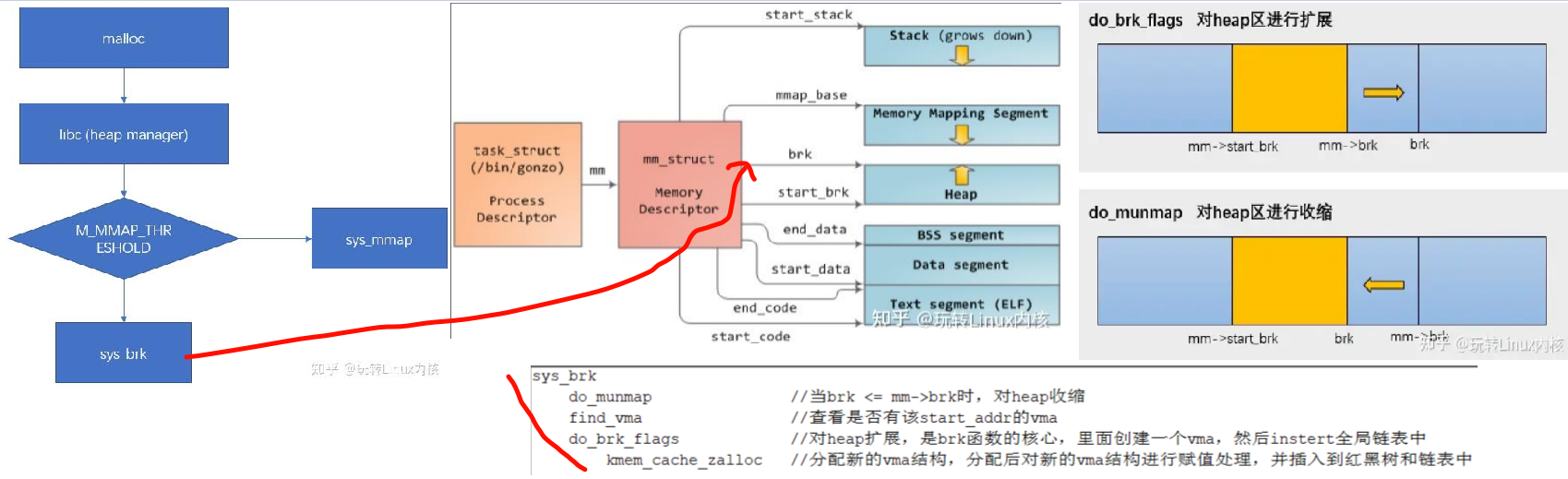
Glibc的malloc首先会通过syscall brk来分配内存,失败的时候fallback到mmap分配。
但是这两个syscall都没有分配真实的物理内存,只是找到一段空闲的虚拟内存VMA(do_brk中不会调用alloc_page分配物理内存)。
只有当这块VMA被访问的时候,由于没有映射到真实的物理内存,而产生page fault事件,在handle_mm_fault中调用alloc_pages来分配真实的物理内存,创建PTE页表项。
使用内存-缺页处理 - Page Faults
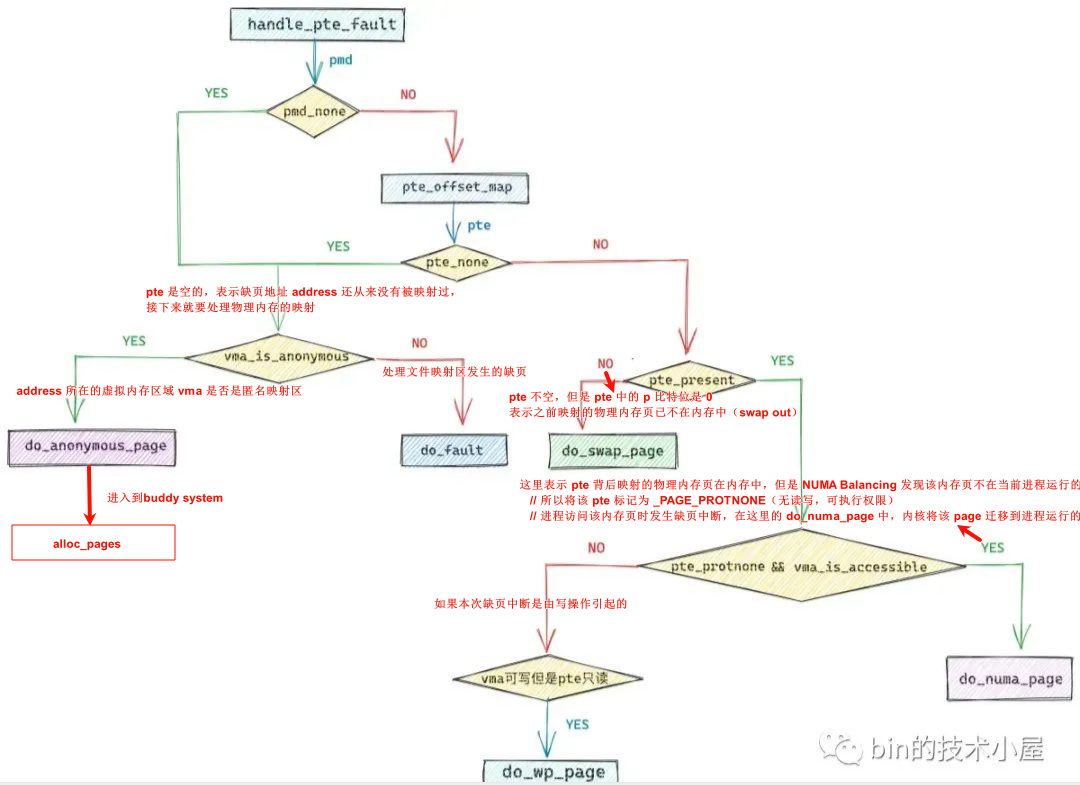
从总体上来讲引起缺页中断的原因分为两大类:
缺页虚拟内存地址背后映射的物理内存页不在内存中
- 缺页虚拟内存地址在进程页表中间页目录对应的页目录项
pmd_t是空的,我们可以通过pmd_none方法来判断。 - 对应的
pmd_t虽然不是空的,页表也存在,但是address对应在页表中的pte是空的。内核中通过pte_offset_map定位address在页表中的pte
既然之前都没有被映射,那就建立映射就好了,有四种内存映射方式:私有匿名映射,私有文件映射,共享文件映射,共享匿名映射。这四种内存映射方式从总体上来说分为两类:一类是匿名映射,另一类是文件映射。
在处理文件映射的代码中,内核调用了一个叫call_mmap的函数,内核在该函数中将虚拟内存的相关操作函数vma->vm_ops映射成了文件相关的操作函数,比如ext4_file_vm_ops。正因为如此,后续进程读写这块虚拟内存就相当于读写文件了。
而在处理匿名映射的代码中,内核调用了一个叫做vma_set_anonymous的函数,在这里会将vma->vm_ops设置为 null ,因为这里映射的匿名内存页,背后并没有文件来支撑。
- 虚拟内存地址address在进程页表中的页表项pte不是空的,但是其背后映射的物理内存页被内核
swap out到磁盘上了,CPU 访问的时候依然会产生缺页。
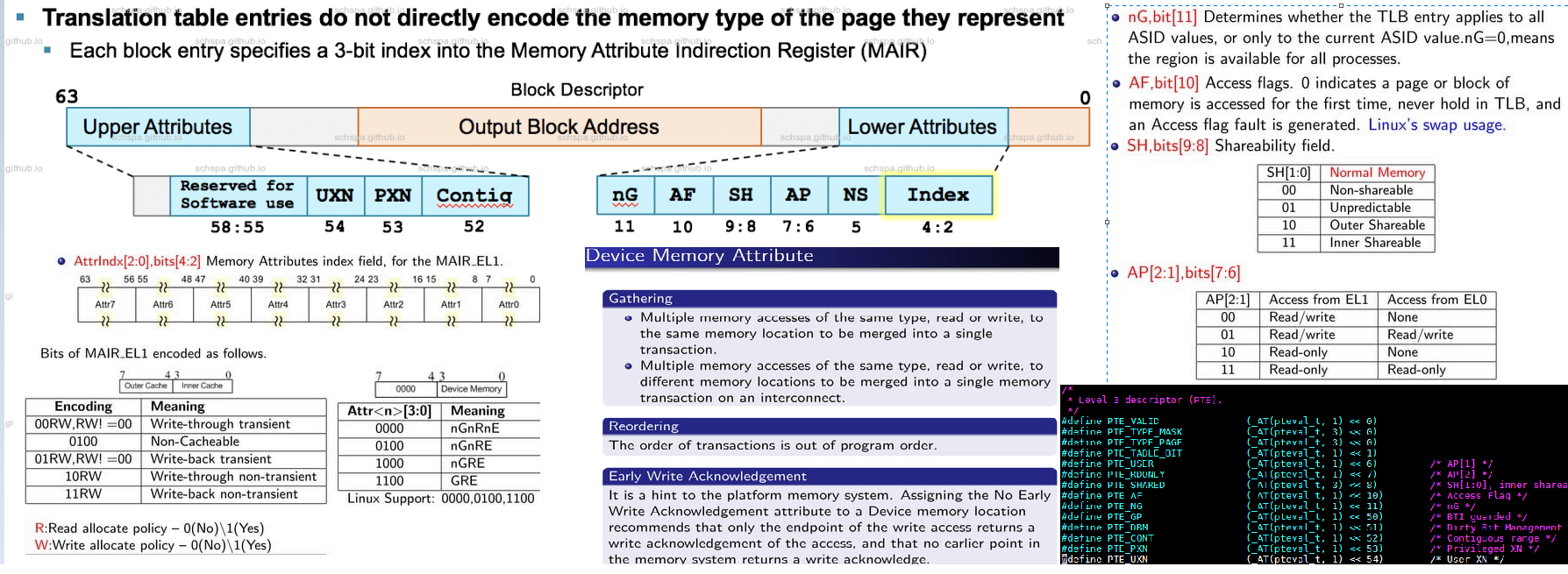
X86上pte的第0个比特位表示该pte映射的物理内存页是否在内存中,值为1表示物理内存页在内存中驻留,值为0表示物理内存页不在内存中,可能被 swap 到磁盘上了。

ARM64上PTE稍有不同,格式如下:
缺页虚拟内存地址背后映射的物理内存页在内存中
- NUMA Balance导致的。NUMA Balancing会周期性扫描进程虚拟内存地址空间,如果发现虚拟内存背后映射的物理内存页不在当前CPU本地NUMA节点的时候,就会把对应的页表项pte标记为
PAGE_NONE,随后会将pte的Present位置为0,导致缺页中断。
这里需要调用 do_numa_page,将这个远程 NUMA 节点上的物理内存页迁移到当前 CPU 的本地 NUMA 节点上,从而加快进程访问内存的速度。
- 写时复制(Copy On Write, COW),这种场景和 NUMA Balancing 一样,都属于缺页虚拟内存地址背后映射的物理内存页在内存中而引起的缺页中断。
写时复制应用场景中都有一个共同的特点,就是进程的虚拟内存区域vma的权限是可写的,但是其对应在页表中的pte却是只读的,而pte映射的物理内存页也在内存中。
缺页处理的整体流程如下:
内存回收 - 内存不够时怎么办?
这里的内存回收不是说内存释放(free)。
内存回收建立在LRU链表(lruvec)和LRU缓存(pagevec)两个数据结构的概念之上,lruvec站在numa节点的角度,而pagevec站在cpu节点的角度,
同时,可以认为pagevec是per cpu的lru cache,页面先放入当前CPU的lru cache(pagevec)中,直到pagevec中已经积累了PAGEVEC_SIZE(15)个页面,再获取lruvec的lru_lock,将这些页面批量放入lruvec中。
它们间的关系如下:
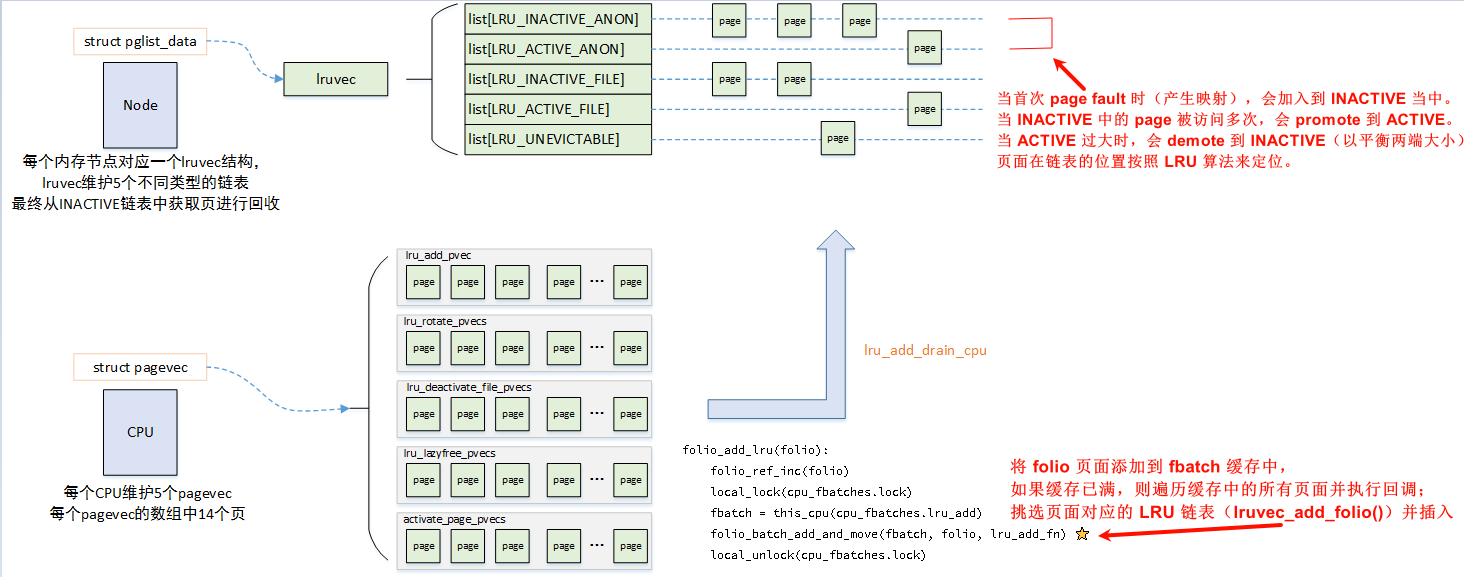
那页面回收时,实际上就是以numa node为基础,针对lruvec进行页面回收。
回收的算法就叫做PFRA(page frame reclaiming algorithm),这个算法主要要做的就是:
- 回收什么样的页面
- 什么时候回收 &如何回收
回收什么样的页
不可回收页
空闲页:已经在伙伴系统中的页,如前边分析,我们回收页的最终去向是伙伴系统,因此已经在
free_list中的页是不无须也无法再回收的。保留页:被标记为
PG_reserved的页,一般这些用都是用来重要部分的内存,例如内核镜像位置、驱动的重要区域锁定页: 被标记为
PG_locked的页,锁定页通常是正在使用的页,比如正在写入或者读取的page cache页,这种页由于正在使用中,所以也不能进行操作。
另外下边这些页由于是在内核态,涉及到操作系统本身的运行,因此也是不可以回收的:
内核动态分配页:用kmalloc申请的内存和slab中已经分配的内存(被标记为
PG_slab)。进程内核态堆栈页:
task_struct对应的内存空间,释放了就找不到进程对应的信息了。
可回收页
可回收页:匿名页,通常就是有malloc申请出来的页,一般通过检查
PAGE_MAPPING_ANON来看是否是匿名页;还有Tmpfs文件系统的映射页可同步页:通过执行sync操作把页的内容写回到磁盘中,再进行回收利用,也被叫做脏页,包括:映射页、存有磁盘文件数据且在页高速缓存中的页、块设备缓冲区页和某些磁盘高速缓存的页(如索引节点高速缓存)。
可丢弃页: 内存高速缓存中的未使用页(如slab分配器高速缓存),分配在slab中,但是还空闲没有被使用的部分,可以被系统通过slab分配器主动回收; 目录项高速缓存的未使用页,用于缓存文件系统中的目录项(dentry)。目录项表示了文件系统中文件和目录的结构。
什么时候回收&如何回收
有两种回收方式,直接回收和异步周期回收。
异步周期回收一般就是kswapd,当空间内存低于水位时,开始执行。
直接回收是在alloc_page时,且水位低于min时,直接调用kswap,回收内存。
整体如下:
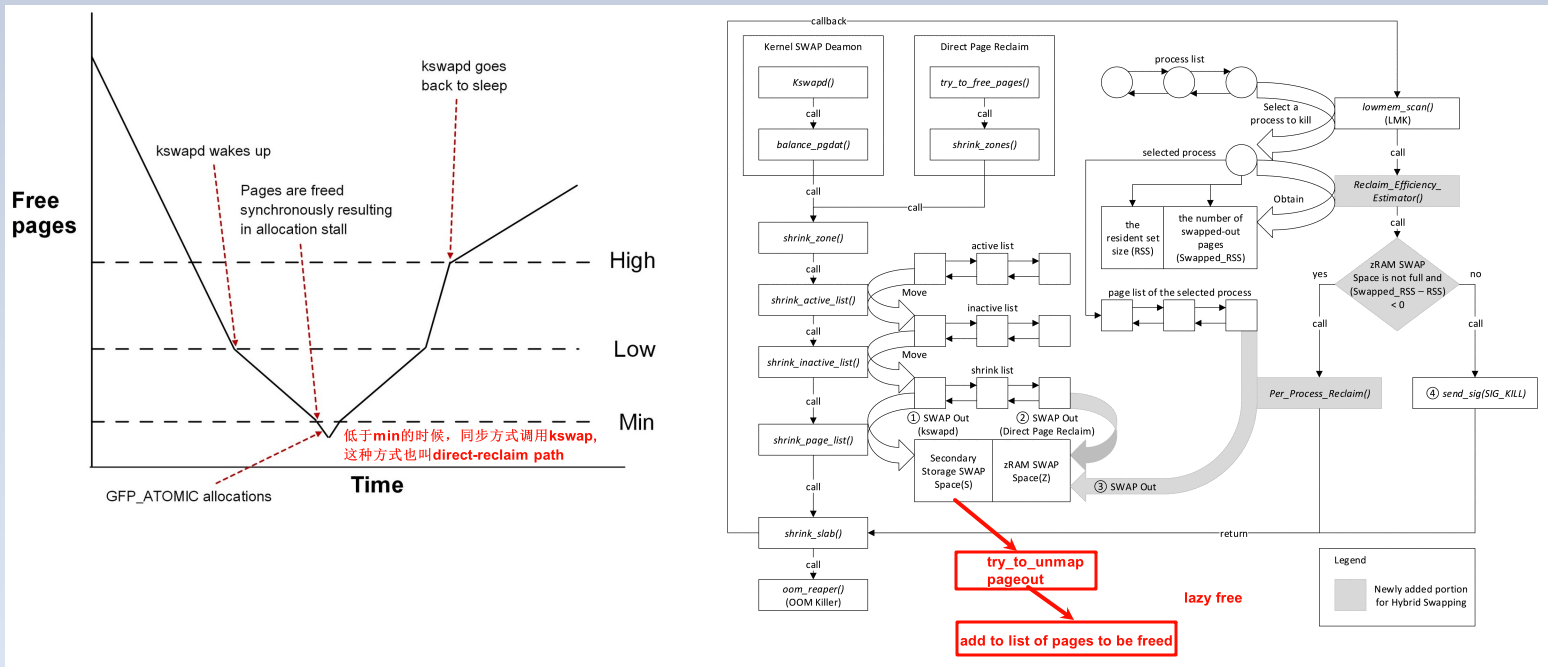
详细的代码流程可以参考 Linux内存管理 - zoned page frame allocator - 5
swap
由于内存和磁盘的读写性能差异较大,Linux会在内存充裕时将空闲内存用于缓存磁盘数据,以提高I/O性能。相对的在内存紧张时Linux会将这些缓存回收,将脏页回写到磁盘中。
而在进程的地址空间中,如heap,stack等匿名页,在磁盘上并没有对应的文件,但同样有回收到磁盘上以释放出空闲内存的需求。
swap机制通过在磁盘上开辟专用的swap分区作为匿名页的backing storage,满足了这一需求。
Linux中存在两种形式的swap分区:swap disk和swap file。前者是一个专用于做swap的块设备,作为裸设备提供给swap机制操作;后者则是存放在文件系统上的一个特定文件,其实现依赖于不同的文件系统,会有所区别。
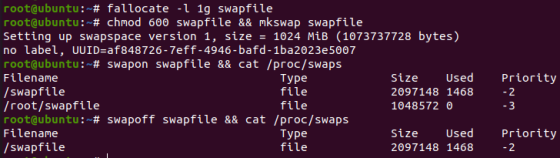
通过mkswap命令可以将一个swap disk或swap file转换为swap分区的格式。随后可通过swapon和swapoff命令开启或关闭对应的swap分区。通过cat /proc/swaps或swapon -s可以查看使用中的swap分区的状态。
一个swap_info_struct对应一个swap分区。如下图所示,swap分区内部会以page大小为单位划分出多个swap slot,同时通过swap_map对每个slot的使用情况进行记录,为0代表空闲,大于0则代表该slot被map的进程数量。
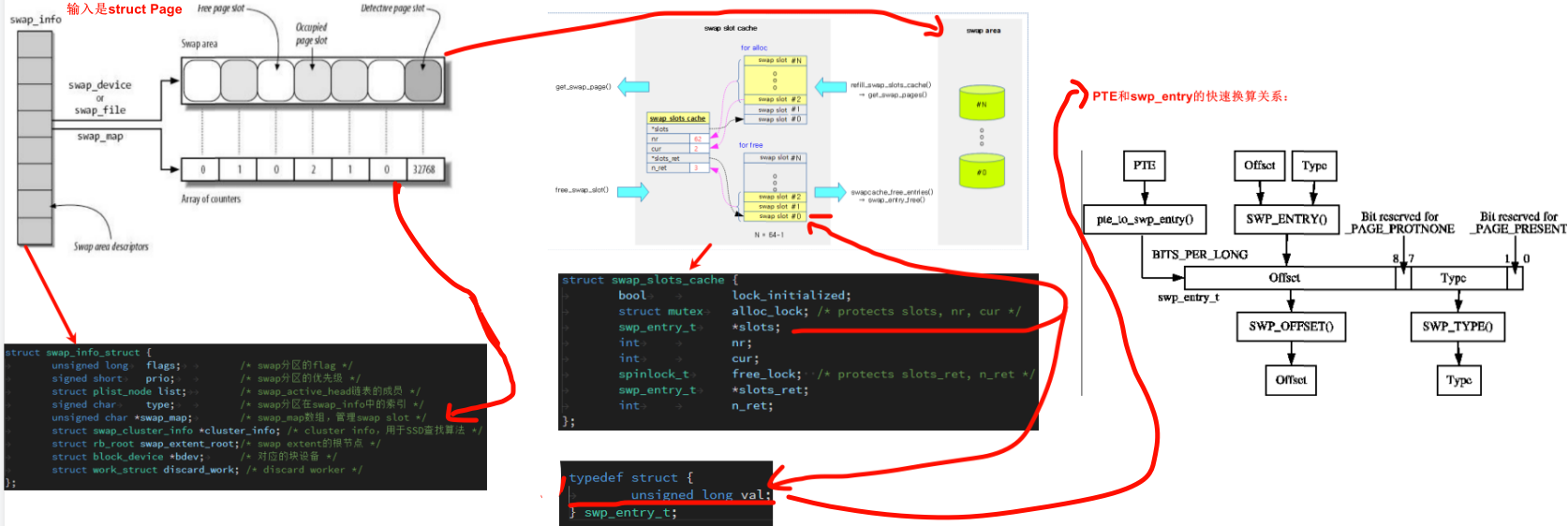
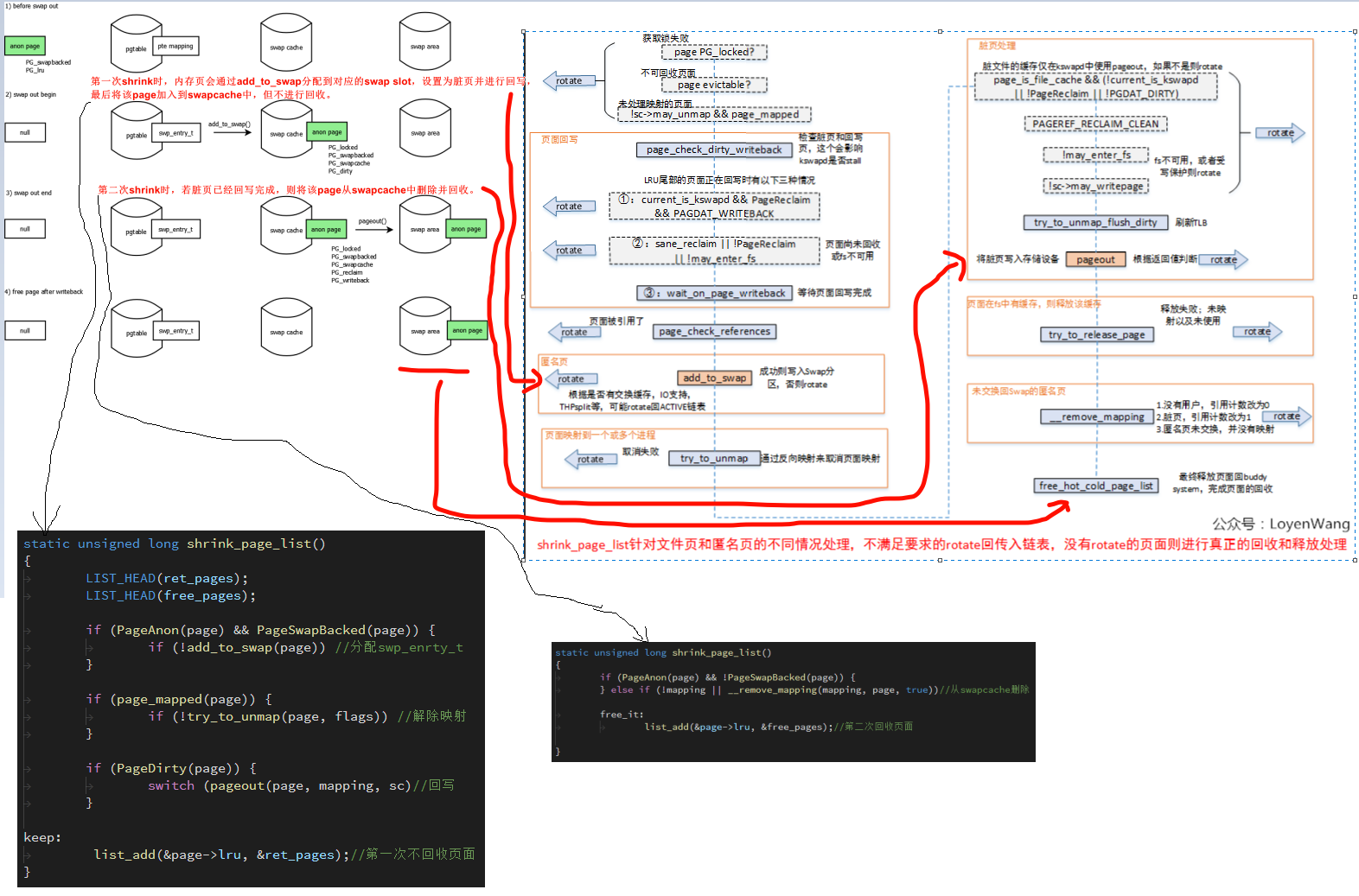
swap流程如下:
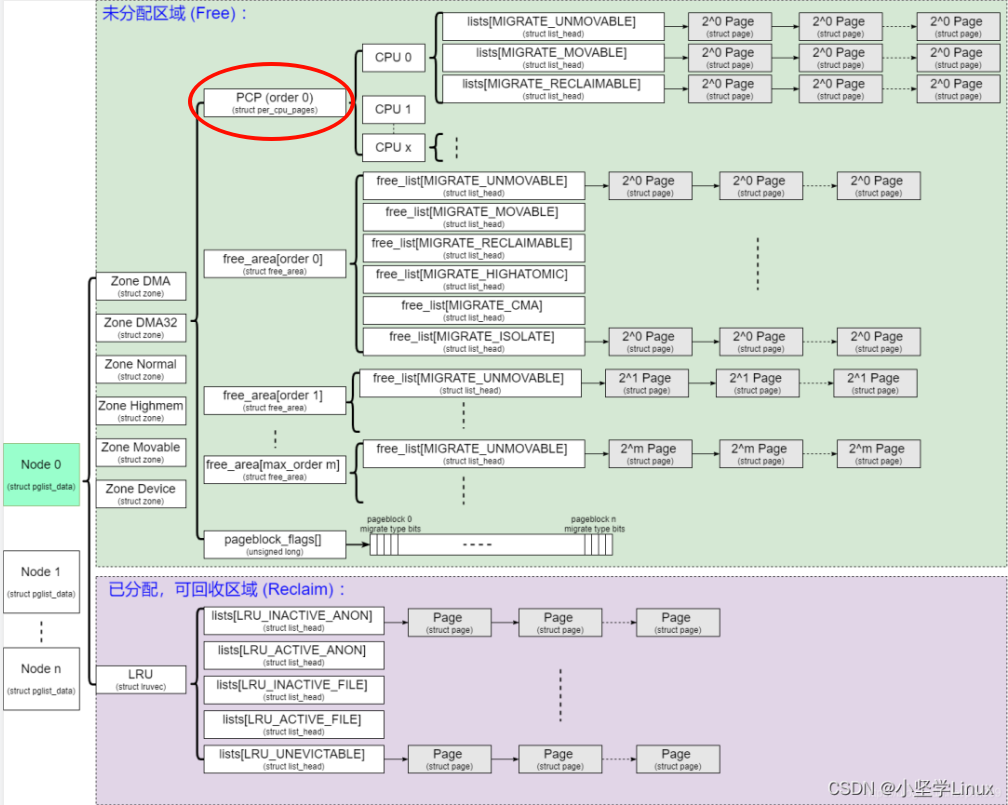
内存冷热
所谓冷热是针对处理器中的cache来说的,冷就是页不大可能在cache中,热就是有很大几率在cache中。
cold page和hot page的概念可以参考LWN的文章Hot and cold pages,从2.5.45内核,Martin Bligh和Andrew Morton提交了一个内核分配器patch,引入了hot-n-cold pages的概念。
该patch在 struct zone 下引入了 struct per_cpu_pages,同时修改了内存分配的流程,加快了分配速度。
内存分配的修改主要是优先从PCP中分配order为0的page,细节流程如下:
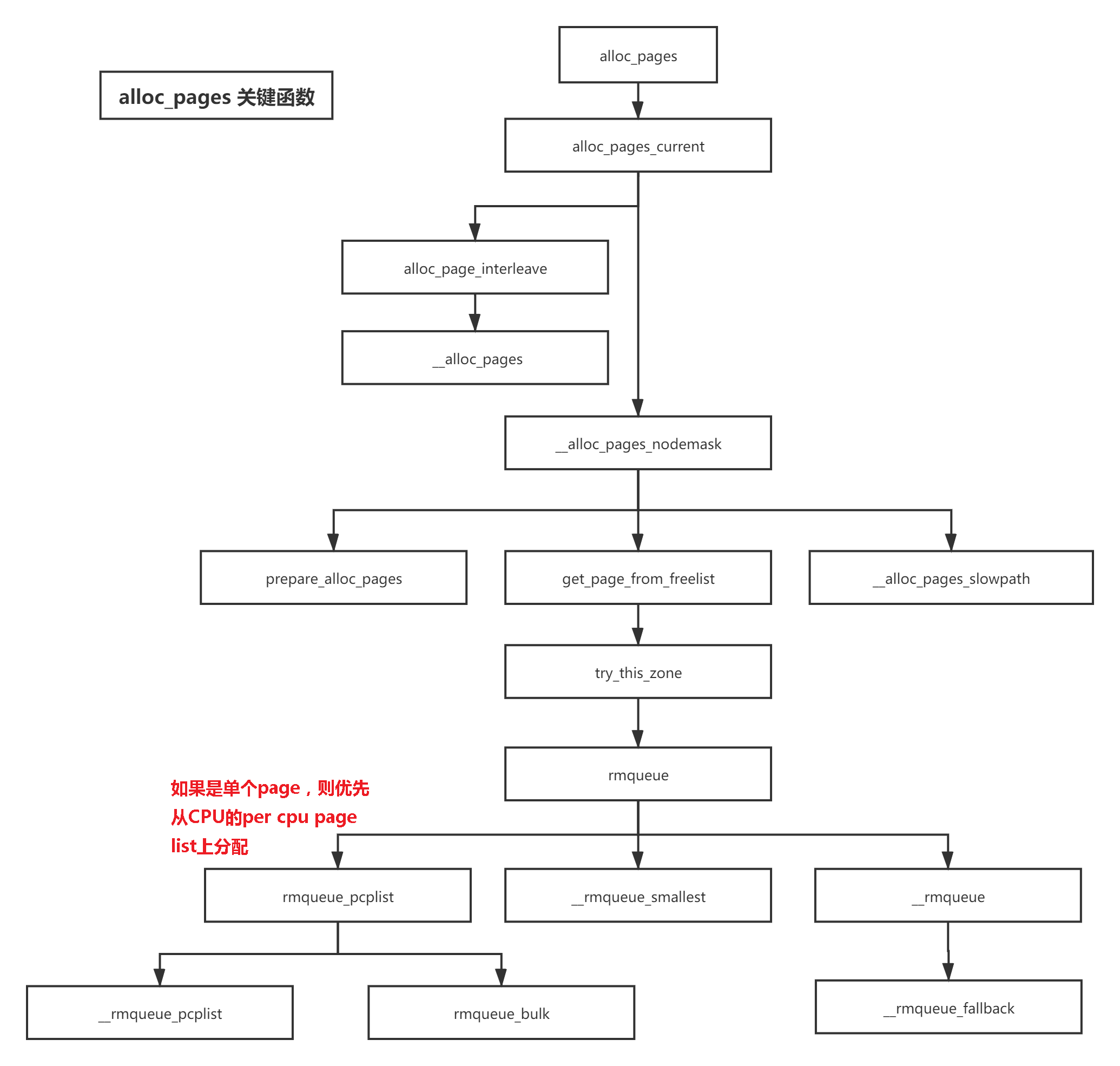
把rmqueue打开,更细的流程如下:
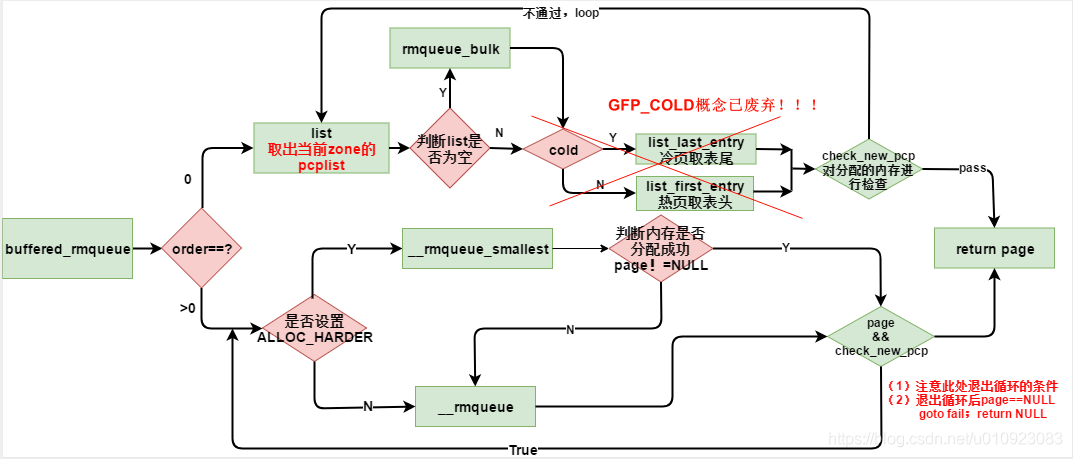
当kernel需要分配一个page时,通常会从per-CPU的hot list获取页面。当然也有些情况下,申请hot page不会获得性能上的提高,只要申请cold page就可以了。比如DMA读操作需要的内存分配,设备会直接修改内存并且无效相应的cache,所以内核分配器提供了GFP_COLD分配标记来声明从cold page链表分配内存。buffered_rmqueue用于从冷热分配器中分配单页的缓存页。如果gfp_flags中指定的__GFP_COLD,则从冷缓存中分配一页,否则,从热缓存中分配。
remove GFP COLD
2017年11月,Gormen在内核4.14里面又删掉了GFP_COLD的概念,详细参考这个patch mm: remove __GFP_COLD。
但是PCP的概念仍然保留,这样分配单页仍然会先走PCP,释放的时候也会释放到PCP中。
层级内存 demotion & promotion
现在有了层级内存之后,实际上就是在swap之前,把这个页移动到延迟更大的内存上,整体思路如下:
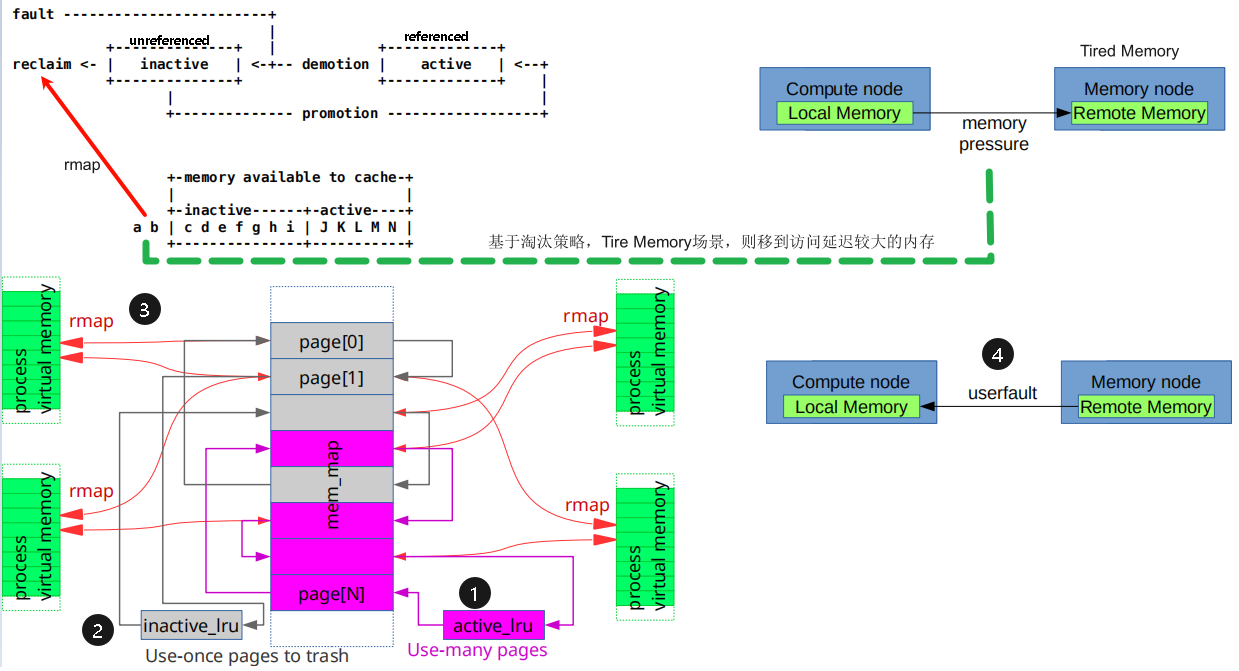
demotion
demotion的关键patch是这个mm/migrate: demote pages during reclaim。
道理很简单,就是在shrink_folio_list中,swap之前,找到一个可以demote的numa node,然后通过migrate_pages把页面迁移过去。
shrink_folio_list
can_demote
demote_folio_list
migrate_pages
完整的逻辑可以参考这个patch set mm/demotion: Memory tiers and demotion
promotion
promotion主要还是基于前面讲的page fault中的numa balance。
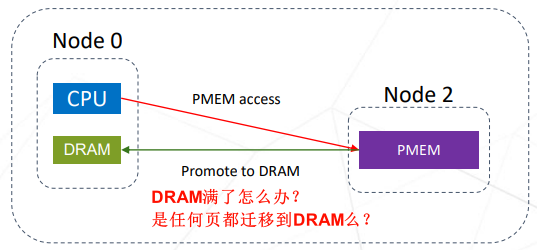
为了优化性能,社区有做了些优化
- 慢速内存判热promotion: memory tiering: hot page selection
- 迁移过程中,减少TLB miss: LUF(Lazy Unmap Flush) reducing tlb numbers over 90%
参考
- Optimize Page Placement in Tiered Memory System
- Lightweight Frequency-Based Tiering for CXL Memory Systems
- Understanding the Linux Virtual Memory Manager
- Linux进程的内存管理之malloc和mmap
- uCore OS实验指导书和源码网址
- 一文聊透 Linux 缺页异常的处理 —— 图解 Page Faults
- Describing Physical Memory
- linux内核(5.4.81)—内存管理模块源码分析
- [内核内存] 伙伴系统5—buffered_rmqueue(页面分配核心函数)
- A Hybrid Swapping Scheme Based On Per-Process Reclaim for Performance Improvement of Android Smartphones (August 2018)
- Linux Swap 介绍
- Linux内存管理 - zoned page frame allocator - 5
- Better caching using reinforcement learning
- 20 YEARS OF LINUX VIRTUAL MEMORY
- 20 YEARS OF LINUX VIRTUAL MEMORY
- Linux mem 2.4 Buddy 内存管理机制
- 内存管理4-页面回收
- linux内存回收(一)—kswapd回收
- Memoptimizer watches your memory usage so you don’t have to!
- 一张图看懂linux内核中percpu变量的实现
- ARM64 Page type
- linux kernel 宏展开
- 冷热页机制
- 单机Mem冷热追踪
- 内存满了,会发生什么?
- Using Linux Kernel Memory Tiering
- linux 内存回收lru算法代码注释1
- Linux Swap 从 userspace 到 kernel详解
- Linux 内核的内存回收机制
- Linux中的内存回收
- 内存
- 15-内存管理篇(Part1: 原理 + page.s + swap.c)
- How The Kernel Manages Your Memory
- armv8 memory system

