Google检索p2p dma能发现好多技术名词,什么p2pdma, dma-buf, GPUDirect, NVMEoF-P2P, SPIN, XDMA, Donard等等,
自然而然就陷入了疑惑,为什么会有这么多解决类似问题的方案呢?它们之间又是什么关系呢?又有什么区别呢?哪种场景下该用哪个技术呢?差异在哪里呢?
本文在AMD GPU的maintainer Alex Deucher总结材料上,补充些信息,做个总结。
Out of tree方案(暂未何如到linux kernel主线)
MLX的PeerDirect方案
之前已经介绍过这个技术,就不重复了,想详细了解的可以翻翻以前的文章,也可以看看官网。
这个方案依赖MLX定制的infiniband内核ko,相关的patch Peer-direct memory并没有被主线接受,
这组patch的开发过程可以参考这个链接。
主要有几个点:
- 外设需要使用ib_register_peer_memory_client把自己的内存注册到IB空间中,同时实现自己的内存管理回调函数,比如分配,映射等,后面几步会利用这些回调函数。
- 在用户程序register mr的时候,IB Core会尝试调用每个client的acquire函数,让每个client判断自己有没有办法将给定的虚拟地址区间翻译成物理页面。若能成功,就返回True,表示这段内存由该设备来处理
- IB core找到正确的peer client之后,就会调用其get_pages()函数来将虚拟地址区间翻译成物理页面。
- IB core再调用dma_map()来由物理页面map到bus address即dma_address,并将结果保存在sg_head里(sg_head是调用者传入的一个scatterlist指针, scatterlist专门用来描述一组物理内存)。 nv_peer_mem会使用nvidia_p2p_dma_map_pages()。nvidia_p2p_dma_map_pages()需要传入peer device,正巧ib_core也会将dma_device传入dma_map()里。
如果想看看结合用户态具体怎么用的话,可以参考修改后的ib perftest。
参与这个方案开发的Stephen Bates(Donard系统的作者)后来成为了存储计算芯片公司Eideticom的CTO。
Nvidia的GPUDirect方案
这个方案其实和MLX很有渊源,因为GPU的一个主要使用场景就是通过RDMA技术去访问远端的数据。nv_peer_memory的代码实现基本和MLX方案的io_peer_mem基本一致。
有兴趣的可以看看参考方案的用例代码。
它依赖MLX定制的infiniband内核ko,相关的patch并没有被主线接受。
对端设备侧的驱动也需要修改,所以Nvidia的GPU还写了一个nv_peer_memory的ko实现内存管理等回调函数,
它把GPU的内存通过ib_register_peer_memory_client函数注册到rdma的环境中。
另外在再做具体地址映射时,又依赖nvidia-peermem.ko。
AMD的kfd_peerdirect方案
这个方案实际上也是基于MLX的方案的,代码和Nvidia的实现很相似,详细可以看看源码。
Donard方案
这个方案其实可以算是MLX方案,这个作者和基于MLX的方案开发了Donard系统,后面演进成p2pdma方案了。
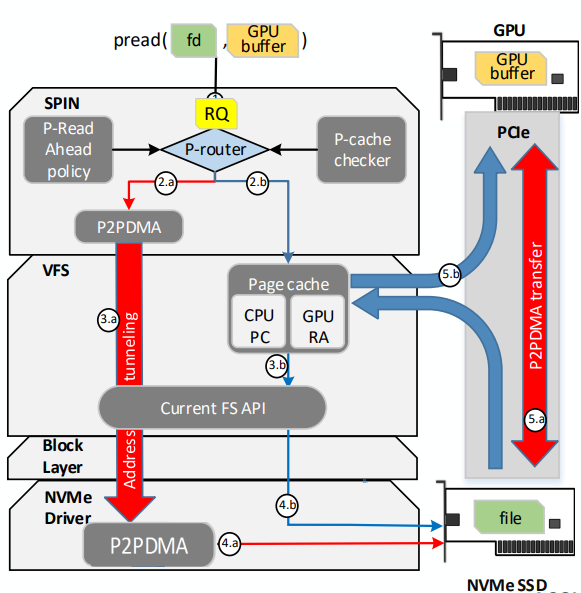
SPIN方案
这是以色列理工学院Technion Accelerated Computing Systems Lab推出的方案,功能是把ssd上的数据直接读到GPU的vram。
由于只是一个学术demo方案,所以代码比较粗糙,主要实现一个设备驱动,提供ioctl支持读和分配内存的操作,并截获pread系统api,打开之前定义的设备进行ioctl操作。
更详细的信息可以参考其官网
Fusion-io ioMemory方案
Fusion-io是一家做SSD和nvdimm的公司,他们这个方案主要是配合Nvidia的GPU面向CUDA应用的。
其实也是基于Nvidia的GPUDirect方案的,而且这家公司在2014年已经被SanDisk收购了,在这里就不做更深入的介绍了。
细节可以参考源码

iopmem
这个方案更像是一个demo,它基于ZONE_DEVICE,只是把设备的内存映射到CPU地址空间中,供其它设备使用。
细节请参考 源码
In tree方案(已经合入到linux kernel主线)
ZONE_DEVICE IO
随着persisttent memory设备的兴起,为了在kernel中能使用这些设备的内存,ZONE_DEVICE的概念被引入了内核。
一开始的时候这些内存并不支持页表形式的管理,但4.3之后,内核中引入了devm_memremap_pages 这个API,使用该API注册的设备内存将会映射到内核的virtual address space中。
但是并不提倡针对大容量内存的设备使用这个API,因为会浪费掉很多system memory管理页表。
更详细的使用限制可以 这个链接。
P2P PCI方案
这个方案的代码在内核的driver/pci/p2pdma.c中,当前内核只支持NVMe,用户态SPDK支持,但设备侧的内存需要基于page管理,这也就意味着这个方案对于目前使用ttm管理内存的GPU还不能使用。
之前也有方案不基于page管理,但是 这组patch Removing struct page from P2PDMA 并没有被社区接受。
而且这个方案基于ZONE_DEVICE,这个在arm64平台上默认没有使能。
在使用这个方案的时候,要显式调用p2pdma框架的api,它并没有和内核中dma框架的api合成一套。
比如: https://elixir.bootlin.com/linux/v5.19-rc7/source/drivers/nvme/host/pci.c#L870
但目前社区有 一组patch DMA Mapping P2PDMA Pages把它和dma iommu api框架结合起来。
完整的 仓库链接, 作者居然是Eideticom的CTO。
这个方案还有两个限制:
仅能支持同一个root port下面的end point设备,对于跨root port的,需要修改p2pdma.c显式增加支持。
具体代码修改参考这个链接: https://elixir.bootlin.com/linux/v5.19-rc7/source/drivers/pci/p2pdma.c#L292
原始patch PCI/P2PDMA: start with a whitelist for root complexes
设备内存是pinned住的。
DMA-BUF
这个方案开始的时候并不是用于设备内存的,而是用于系统内存的。
它支持unpin的内存(监听move_notify消息),由于GPU的内存十分宝贵,且需要换入换出,所以在GPU驱动中目前有使用这个方案。
另外这个方案已经和dma iommu框架集成在一起,调用dma_map等api的时候,会自动回调它的相关callback函数。
社区中也有人正在让RDMA设备支持这个方案:RDMA: Add dma-buf support
habanalabs
intel之前收购了以色列的habanalab,他们在2021年也提出了基于DMA-BUF的方案,让设备可以互相访问对方的内存,且也已经合入到了社区。
它提供了一个ioctl,要求用户态发 HL_MEM_OP_EXPORT_DMABUF_FD 命令,把设备的内存暴露到用户态。
但是很可惜,没有找到用户态的例子。
HMM
这个方案开始的时候,也是针对CPU使用异构内存的,也并不是针对设备内存的。
设备内存可以注册到ZONE_DEVICE,但是只能配置成DEVICE_PRIVATE,所以CPU无法访问。
但是呢,社区里也有人让这款内存变成CPU可以访问的,具体参考这个patch:MEMORY_DEVICE_PUBLIC for CPU-accessible coherent device memory
上面这个patch是AMD用于构建自己的超算Frontier,希望CPU可以访问GPU的内存,且支持coherence。
GPU + RDMA + RDMA + NVMe
回过头来,看看我们的场景,希望本地的GPU通过RDMA网卡,访问远程的NVMe SSD存储介质上的文件数据,这种情况下的限制:
- GPU上的内存并不希望被pin住
- RDMA并不支持GPU上的dma_fence同步概念
参考
- Enabling peer to peer device transactions for PCIe devices
- Seamless Operating System Integration of Peer-to-Peer DMA Between SSDs and GPUs
- Why is Peer to Peer DMA so hard on Linux?
- Coprocessor memory definition
- Microsemi PCIE Switch+RDMA
- 浅析nv_peer_memory的实现
- Building Mellanox OFED from source code
- rdma-gpu-direct-for-fusion-io-iodrive
- Minimizing struct page overhead

