感觉这年头干啥芯片的都想把计算绑定在一起,之前有网卡把计算绑一起,现在也有把存储和计算绑一起。
什么是计算存储
其实这要从NVME说起,从NVME 1.2规范引入CMB(Controller Memory Buffer)这个概念起,就慢慢有了变革的火种。
CMB是一段放在NVME卡上的内存,有点类似于独显的显存的概念,也是通过PCIe BAR空间对CPU可见,一开始主要是
把NVME涉及到的SQ和CQ放在这个内存区域,避免访问系统DDR,而起到减小延迟的效果。
那现在有了内存,为什么不参考下GPU,把计算core放进去呢,这样就有了computational storage的概念。
借用下SNIA组织的图,更形象的说明下什么是computational storage:
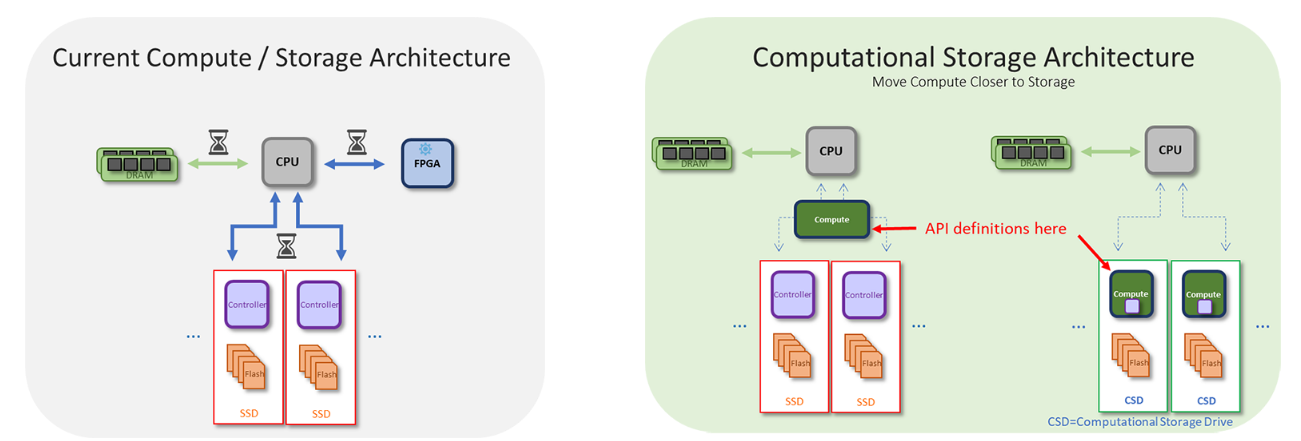
代表公司和产品
推动computational storage的主要有三家初创公司: Eideticom, NGD和scaleflux。
当然还有传统的nvme存储公司比如美光和三星,这几家里面我认为软件生态做的最好的是Eideticom。
它的CTO Stephen Bates在2015年就提出了Donard系统的概念,这个系统当时就把GPGPU、NVMe SSD和RDMA串在了一起,
旁路了CPU,可以认为这是Eideticom的起源之一,感兴趣的朋友可以看看本文的参考资料。
为了对这种产品形态有更直观的感受,放个Eideticom卡的图
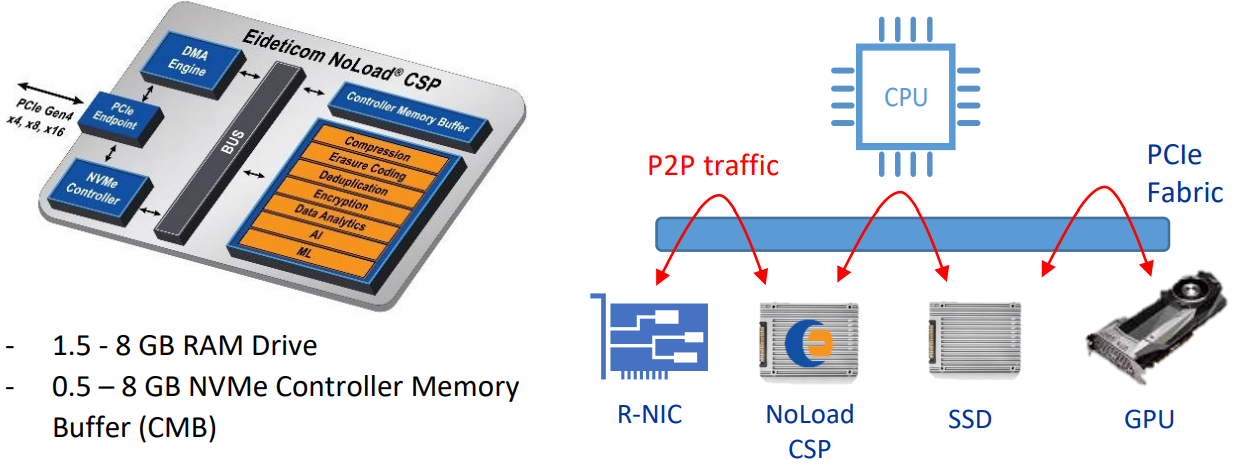
典型的用户场景是通过减少数据移动,把一些原先要在cpu和nvme路径上执行的任务,直接卸载到computational storage processor里面来,提升效率。比如:
- 数据库场景中数据的压缩计算
- 网络数据的存储,这个有点类似于nvme over rdma,且把计算也offload到nvme卡上,具体示意如下:
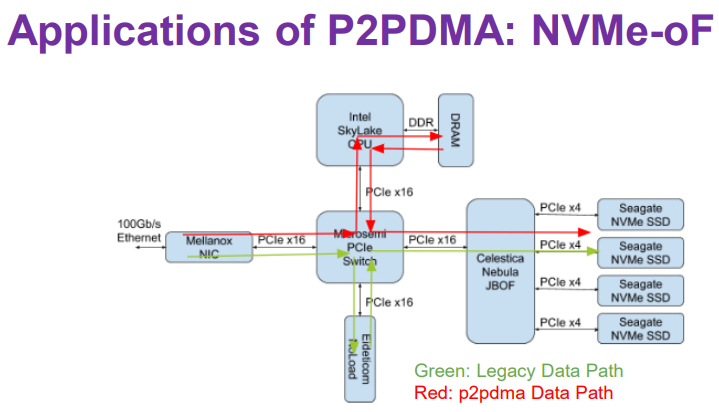
p2pdma
为了让NMVE卡上的这块内存可以被使用,就不得不提p2pdma这个上了linux和qemu主线的方案,
前面也介绍过mlx 的peer to peer direct技术,也介绍过nvidia的 gpudirect技术,但是它们目前都没上linux主线。
p2pdma在内核的pci驱动目录中的p2pdma.c中,从4.20开始被支持,想了解历史的看看这组patch和相关作者的一个总结:
- Copy Offload in NVMe Fabrics with P2P PCI Memory
- p2pdma in Linux kernel 4.20-rc1 is here!
- Device-to-device memory-transfer offload with P2PDMA
在这个总结中,作者有提到在arm64上还需要加上ioremap相关的patch才能正常工作,不知道现状如何了。
卡上的内存暴露出来之后,下一步就是怎么把这块内存给用起来。
当前能直接使用p2pdma技术的主要有SPDK,以及Eideticom自家的libnoload。
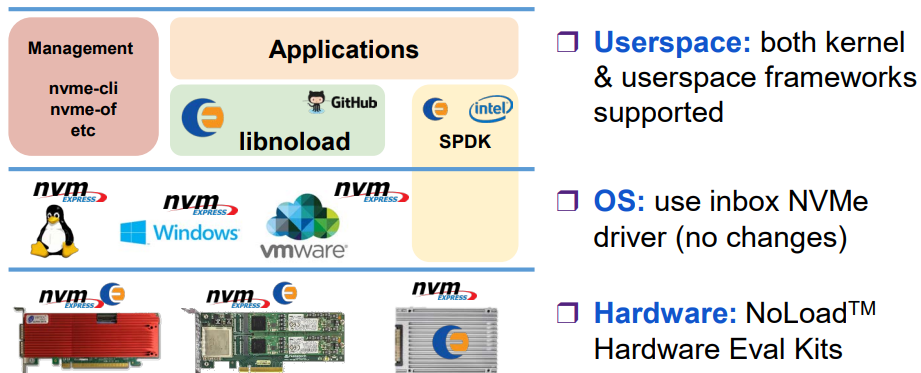
SPDK
这里以SPDK为例,由于spdk是用户态的,所以kernel把bar空间映射到用户态以后,主要是bar,doorbell的操作。
感兴趣的可以直接看spdk中的 cmb_copy.c,感觉用起来还是很简单的。
spdk_nvme_ctrlr_map_cmb
nvme_transport_ctrlr_map_cmb
spdk_nvme_transport_ops.ctrlr_map_cmb
nvme_pcie_ctrlr_map_io_cmb
nvme_pcie_ctrlr_get_cmbsz
spdk_mmio_read
根据暴露出来的bar_va, 计算buf
spdk_mem_register(buf)
spdk_nvme_ns_cmd_read
nvme_qpair_submit_request
nvme_transport_qpair_submit_request
spdk_nvme_transport_ops.qpair_submit_request
nvme_pcie_qpair_submit_request
nvme_pcie_qpair_submit_tracker
nvme_pcie_qpair_ring_sq_doorbell
nvme_pcie_qpair_update_mmio_required
把算力用起来
要把算力用起来,就要借助一个其它的PCIe 设备,比如网卡,可以参考下面的仓库,看看怎么用起来的,主要是把网卡的收到的NVMe包,直接放到NVME卡的CMB中:
- Offload+p2pdma kernel code
- A fork of the Linux kernel for NVMEoF target driver using PCI P2P capabilities for full I/O path offloading
参考
- What Is Computational Storage?
- NVME CMB详解
- Accelerating Storage with NVM Express SSDs and P2PDMA
- p2pdma__why_how_what
- p2pmem github code repo
- NoLoad U.2 Computational Storage Processor
- Enabling the NVMe™ CMB and PMR Ecosystem
- MLX peer memory patch set upstreaming history
- Donard: NVM Express for Peer-2-Peer between SSDs and other PCIe Devices
- An NVMe-based FPGA Storage Workload Accelerator
- Seamless Operating System Integration of Peer-to-Peer DMA Between SSDs and GPUs
- 浅谈GPU通信和PCIe P2P DMA
- Why is Peer to Peer DMA so hard on Linux?
- Coprocessor memory definition
- Microsemi PCIE Switch+RDMA

