作为GPU Direct IO技术的延续,这篇讨论下基于网络的文件系统的底层技术。
综述
借用一幅图,基本上把所有网络存储技术都包含了进来
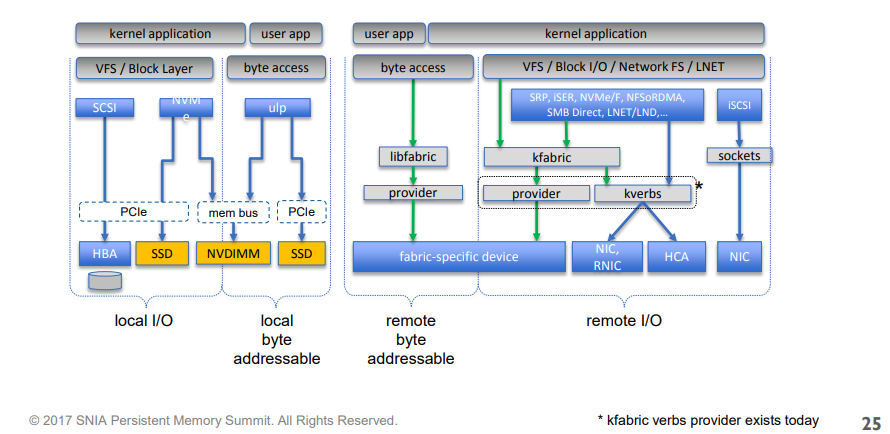
解释下上面涉及到的名词:
- ULP: upper layer protocol,上层协议栈
- libfabric: open fabric(OFED的维护组织)定义的用户态库
- kfabric: open fabric定义的内核模块
- srp: scsi rdma protocl over infiniband
- iser: iscsi extension for rdma
- NVMe/F: NVMe over fabric
- NFSoRDMA: NFS over RDMA
- SMB Direct: server message block, Windows服务器上的技术, MS-SMB
- LNET/LND: Lustre networking,分布式文件系统Lustre的网络技术,其它著名的分布式文件系统还有GlusterFS
- iscsi: scsi based on tcp/ip
DataStorage 和DataAcces的差异
这里要重点强调下这两个概念,数据的存储和数据的访问是两个不同的概念,
存储一般要经过文件系统,而访问是不用的,由于要经过文件系统,他们的延时差异也很大。
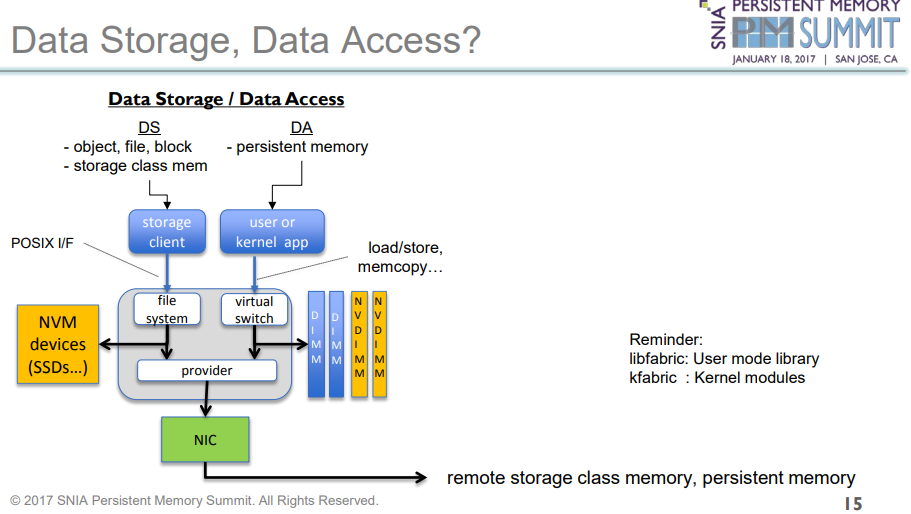
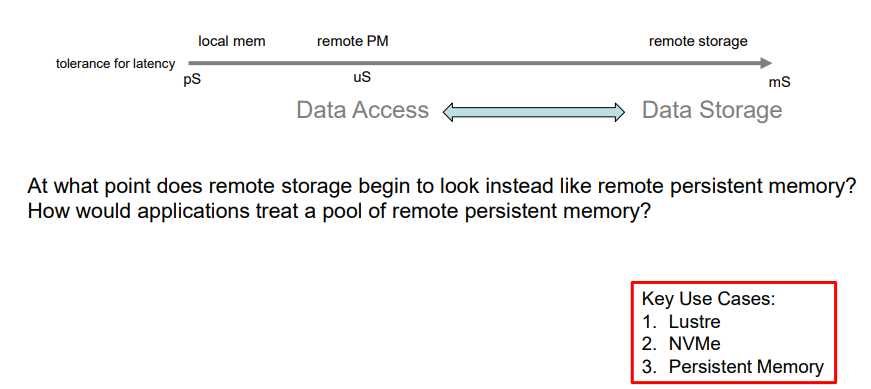
本文只介绍数据存储,接下来围绕开篇提到的几个技术展开。
DAS 直连式存储
讲网络存储之前,还是先介绍下传统的Direct Attached Storage直连式存储。
说白了,就是常见的PC或者服务器直接连着硬盘的。
以常见的scsi为例子,应用下发的文件访问,在scsi层都转换为scsi命令发给scsi存储控制器处理,
对应到kernel中,就是常见的 scsi驱动 了。
如果对整个层次不清楚的话,可以了解下linux storage的全景图:

ISCSI
为了支持网络存储,linux kernel在scsi层下加了一个传输层,把scsi命令通过网络报文发出来。
这个发出报文的client,在scsi命名空间中称为initiator, 而接受处理报文的称为target,这两个名词概念后文会税涉及到。

SRP & ISER
SRP和ISER均能通过RDMA支持SCSI,且都已经被内核支持。
相对来讲,ISER比SRP更好,具体可以从以下几个方面对比:

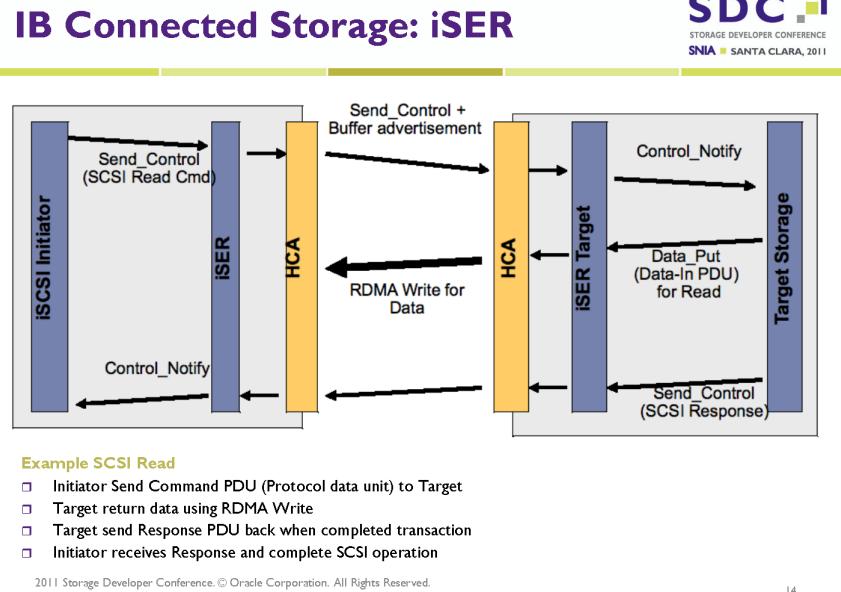
iser典型应用场景如下:
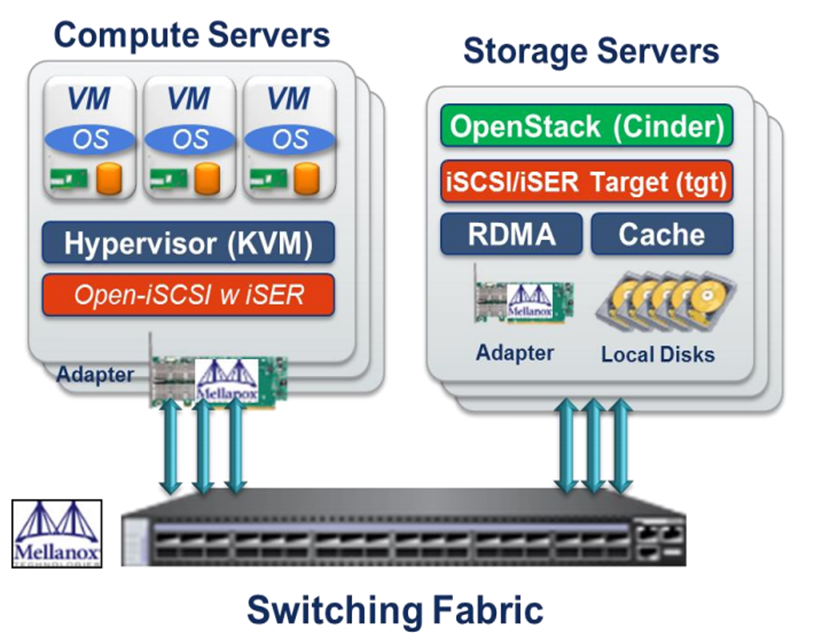
其中的数据流如下:
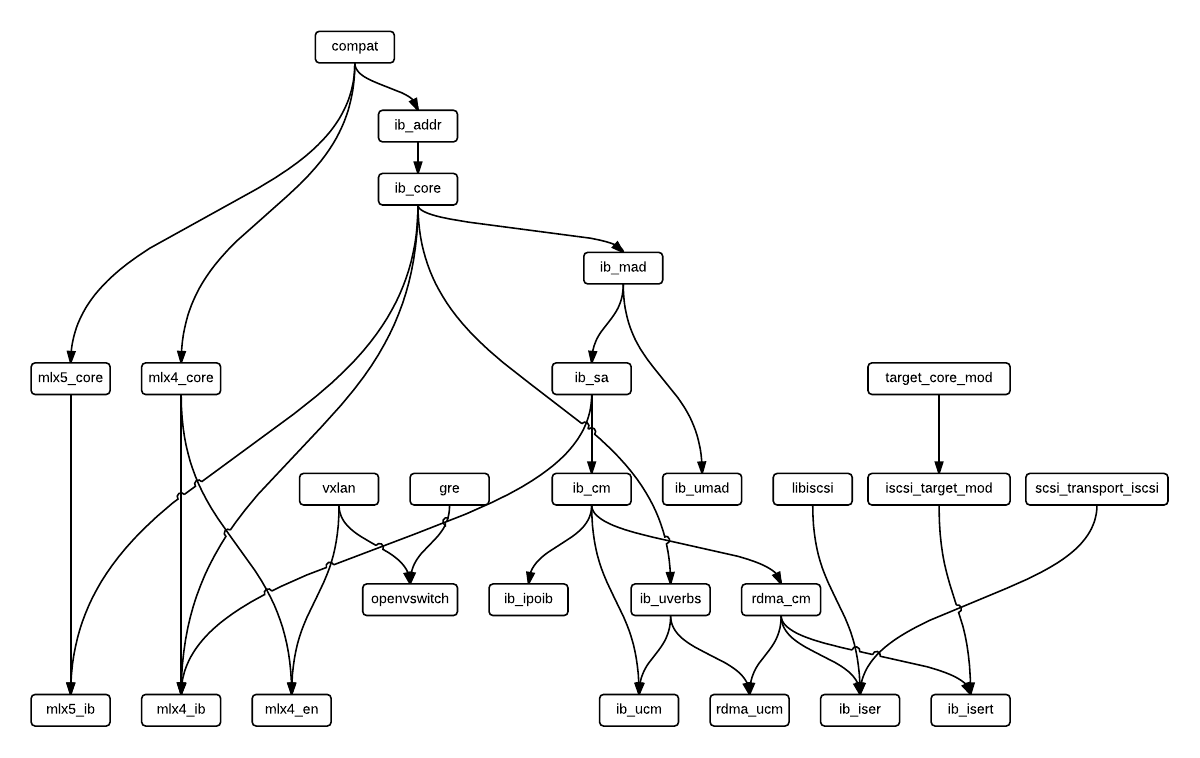
以mlx为例,kernel中的逻辑视图如下:
ISER Initiator
按照道理讲,应该先说Target,再说Initiator比较好,但是由于Target比较复杂,所以放在后G面讲。
假设Target已经配置好,Initator怎么用呢?主要是以下几步:
- discovery:
iscsiadm -m discovery -t st -p target-ip-address - login:
iscsiadm -m node -T iqn.2006-04.com.example:3260 -l - mkfs & mount:
mkfs.ext4 /dev/disk_name; mount /dev/disk_name /mount/point
整个流程如下:
+--------------------------------------------------------+
| Targets & Sessions configuration files and directories |
+--------------------------------------------------------+
+--------------------------+ +----------------------------------+
| iscsiadm | | iscsid: iSCSI daemon |
| | | |
| * Command line tool |<--->| * Implements Session management |
| * Manages database of | | * Communicates with iscsiadm |
| sessions and targets | | and iscsi kernel modules |
+--------------------------+ +---------------+------------------+
|
User space |
- - - - - - - - - - - - - - - - - - - - - - - - - | - - - - - - - - - -
Kernel v
+-----------------------------------------------------------+
| kernel modules: scsi_transport_iscsi, iscsi_tcp, libiscsi |
+-----------------------------------------------------------+
内核中iser intiator位于infiniband/ulp中,它会注册到scsi transport里面,把scsi报文封装到IB报文中。
调用栈如下(不包括scsi层之上)
scsi_transport_iscsi.c
netlink_kernel_create(&iscsi_if_rx)
iscsi_if_rx
iscsi_if_recv_msg
transport->create_session
transport->create_conn
transport->bind_conn
transport->create_session
transport->create_session
ib_isert.ko:
iser_init
iscsi_register_transport(&iscsi_iser_transport)
scsi_lib.c:
scsi_dispatch_cmd
transport::queuecommand
iscsi_queuecommand
iscsi_data_xmit
xmit_task
iser_send_control(registered completed callback iser_ctrl_comp)
ib_dma_sync_xxx
ISER Target
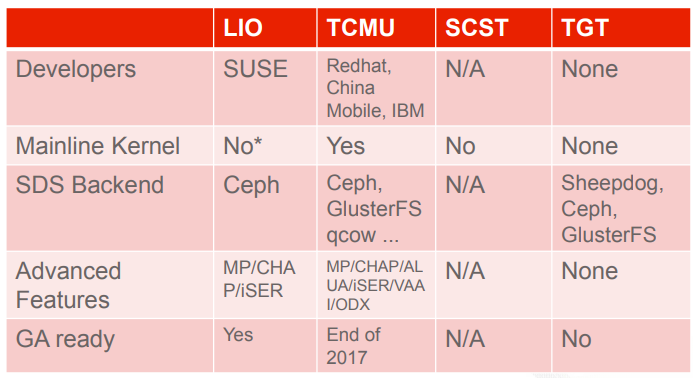
Target侧的实现有很多种方案,主流主要有三种:
- LIO/TCMU: LIO后面名字改成了TCM(Target Core Mod), TCMU是TCM的用户态,已经被Linux Kernel主线支持。由linux-iscsi.org运营维护,主要的开发者是Nicholas A.Bellinger。
- SCST: the generic SCSI target subsystem for Linux,名字最官方,可惜一直没合入到Linux社区,且和LIO的作者一直不合。
- STGT(也叫TGT): 作者是NTT的FUJITA Tomonori和Redhat的Mike Christie,最早的版本是包含内核态的,后面去掉了。
推荐使用LIO/TCMU方案。
其中STGT是纯用户态的,但基本不用了,SCST和LIO/TCMU都有内核模块,但SCST的内核模块并没有合入到内核主线。
更详细的对比可以参考 SCST的官网。
STGT(TGT)
网上的材料都比较老了,很多图里面都画着它有内核态,最初的版本确实是有,只是后面都去掉了,
这个链接的patch是最早在kernel中加入netlink的patch:scsi tgt: scsi target netlink interface
喜欢考古的兄弟可以结合github上老的tag版本结合一起看看。
最新的版本是纯用户态的,iser的支持都在user/iscsi/iser.c中,简单的调用流如下:
iser.c:
iser_device_init
ibv_create_cq
ibv_req_notify_cq
tgt_event_add(cq->fd, &iser_handle_cq_event)
iser_handle_cq_event(如果ib有cq产生,fd唤醒epoll)
iser_poll_cq(ibv_poll_cq)
handle_wc
iser_queue_task
iser_sched_iosubmit
iser_scsi_cmd_iosubmit
target_cmd_queue
cmd_perform
sbc_rw
bs_cmd_submit
bs_rdwr_request
pread/pwrite(系统调用,读写)
tgtd.c:
main
event_loop
epoll_wait(cq->fd)
handler
iser的流程图就不画了,和下面这个tcp的图很类似:
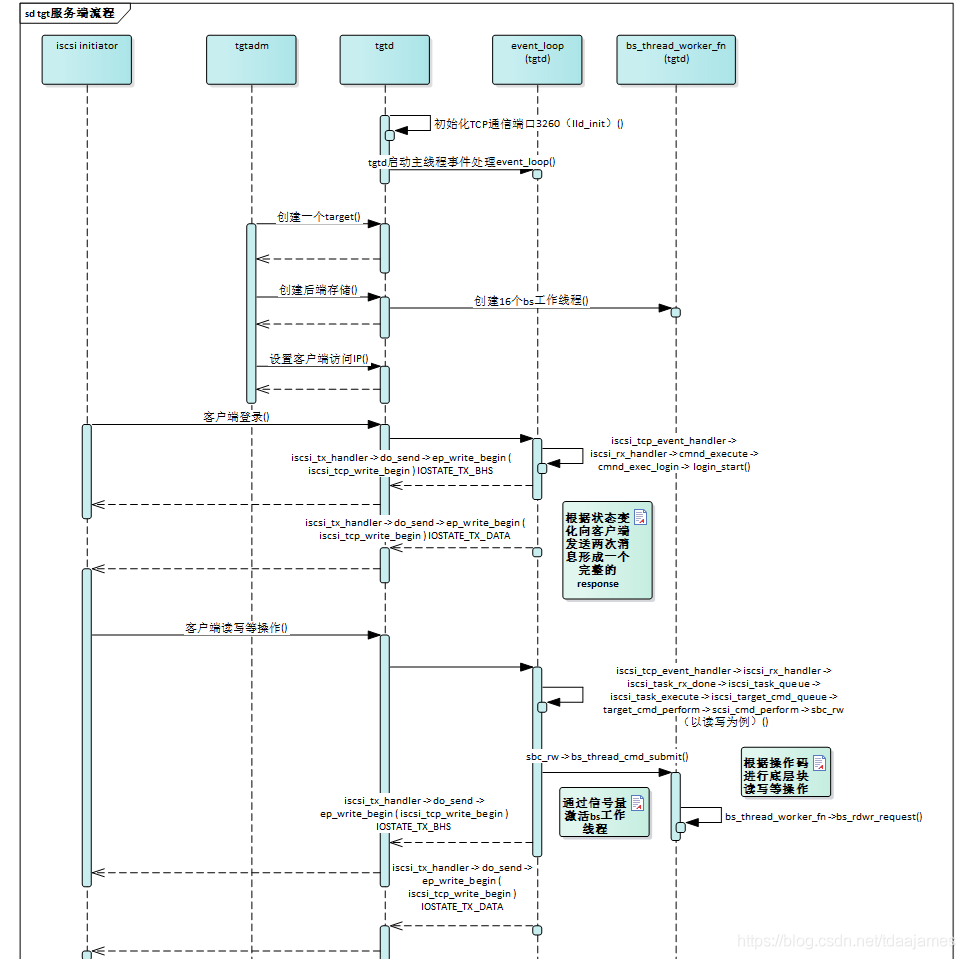
SCST
源码除了从官网下载,也可以从github下载 SCST-project, 其实还是很活跃的,
从2.6到5.14的内核都可以支持,最新的tag版本是v3.6,发布与2022年1月。
SCST的作者和LIO的作者似乎有些不同的意见,在其官网中也一直强调它的优势,由于精力实在有限,就不深入挖掘它的用法了。
David画了一个很漂亮的图:
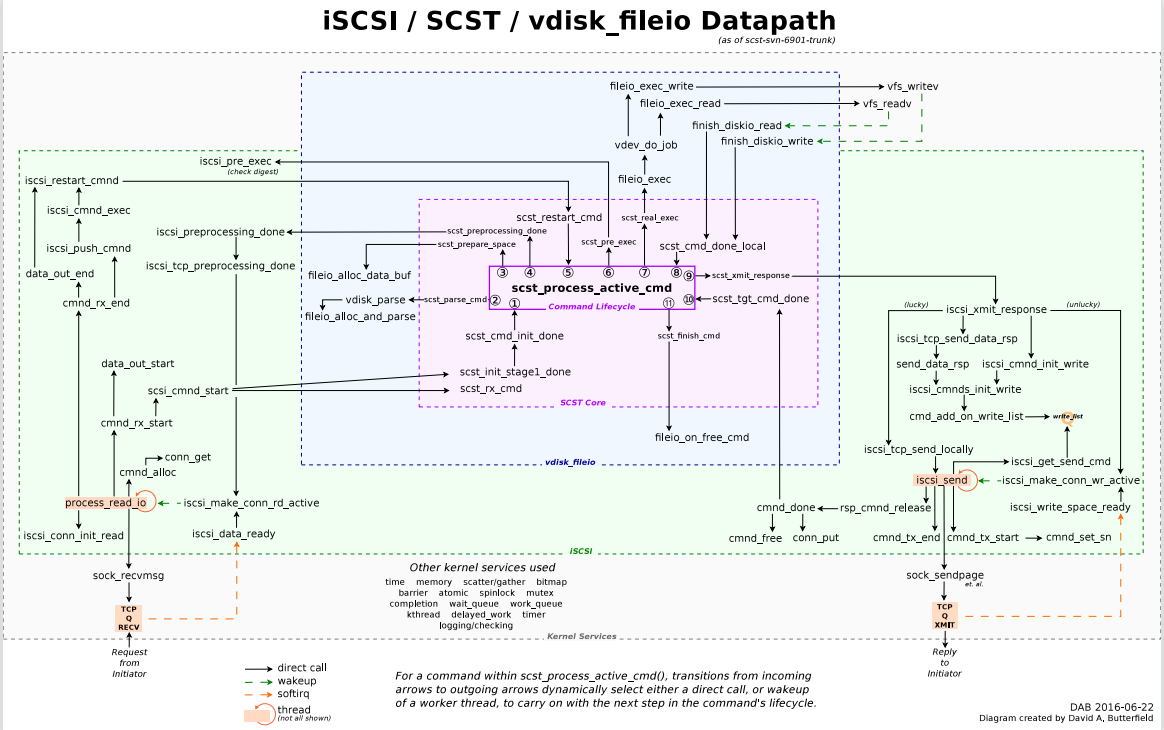
LIO/TCMU
中国移动苏研主推这个方案,且在社区中贡献了不少patch。
主要配置工具是python做的targetcli,它提供了一个交互shell,步骤如下:
- Creating a Backstore
- Creating an iSCSI Target
- Configuring an iSCSI Portal
- Configuring LUNs
- Configuring ACLs
TCMU分为kernel和用户态两部分,用户态现在主要是tcmu-runner, 内核部分主要有以下几个ko:
target_core_usertarget_core_modiscsi_target_modib_isert
他们之间的交互关系如下图:
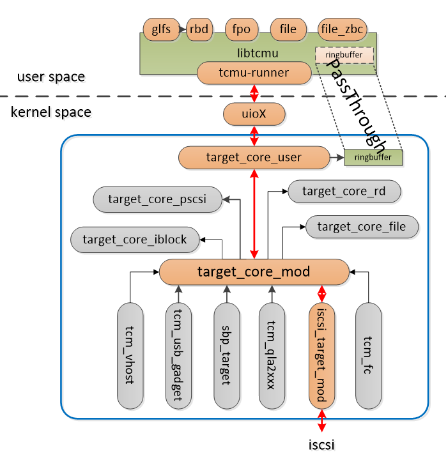
在配置iscsi portal时,会通过ib_isert创建QP,通过中断的方式监听IB报文
lio_target_call_addnptotpg
iscsit_add_np
iscis_target_setup_login_socket
isert_setup_np
isert_setup_id
isert_connect_request
isert_create_qp
ib_cq_pool_get(IB_POLL_WORKQUEUE 内核的IB poll线程监听有没有cq事件,如果有则调用isert_recv_done,监听intiator发过来的报文)
rdma_create_np(isert_qp_event_callback 中断回调函数, 监听硬件中断)
收到报文
isert_recv_done
isert_rx_opcode
isert_handle_scsi_cmd
iscsit_setup_scsi_cmd
target_cmd_parse_cdb
transport->parse_cdb
tcmu_parse_cdb
tcmu_queue_cmd
uio_event_notify 通知用户态
用户态(tcmu-runner)
tcmur_cmdproc_thread
while(1) {
tcmulib_processing_start
read() // block等待,直到收到kernel通知
tcmulib_getnext_command
device_cmd_tail != device_cmd_head //command ringbuffer 中有新的命令
tcmur_generic_handle_cmd
handle_read/handle_write
tcmur_cmd_complete
handle_generic_cbk
aio_command_finish
tcmur_tcmulib_cmd_complete
write() //通知kenrel,处理完command, 触发kernel uio的中断处理
}
用户态处理完报文通知内核:
tcmu_irqcontrol
tcmu_handle_completions
target_complete_cmd
target_complete_ok_work
queue_data_in
lio_queue_data_in
iscsit_queue_data_in
isert_put_datain
isert_rdma_rw_ctx_post
rdma_rw_ctx_post
ib_post_send //通知intiator 处理完
完整的处理流程可以参考下面这个图,虽然不太对得上,但逻辑是ok的
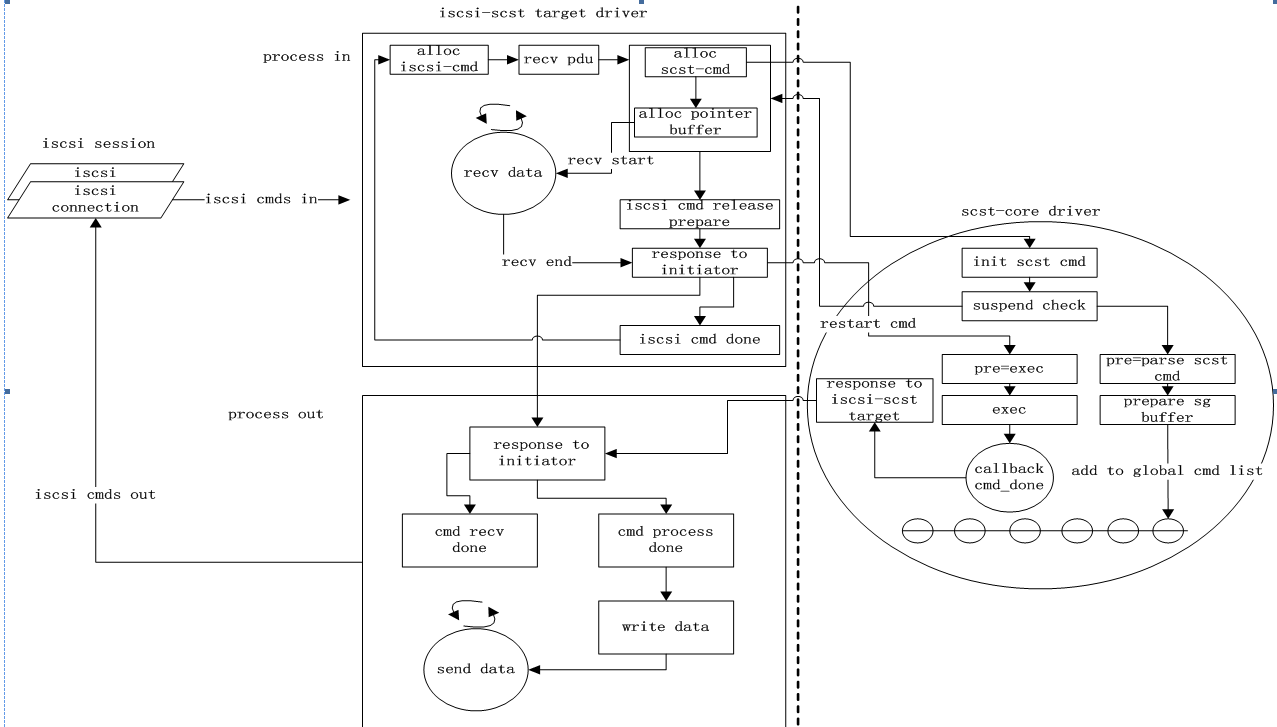
NVMe/F
nvme软件栈相对于scsi来讲,就简单很多,host和target都在内核的drivers/nvme目录下,
而且支持多种传输机制的支持也包含在这个目录中。工作机制如下图:
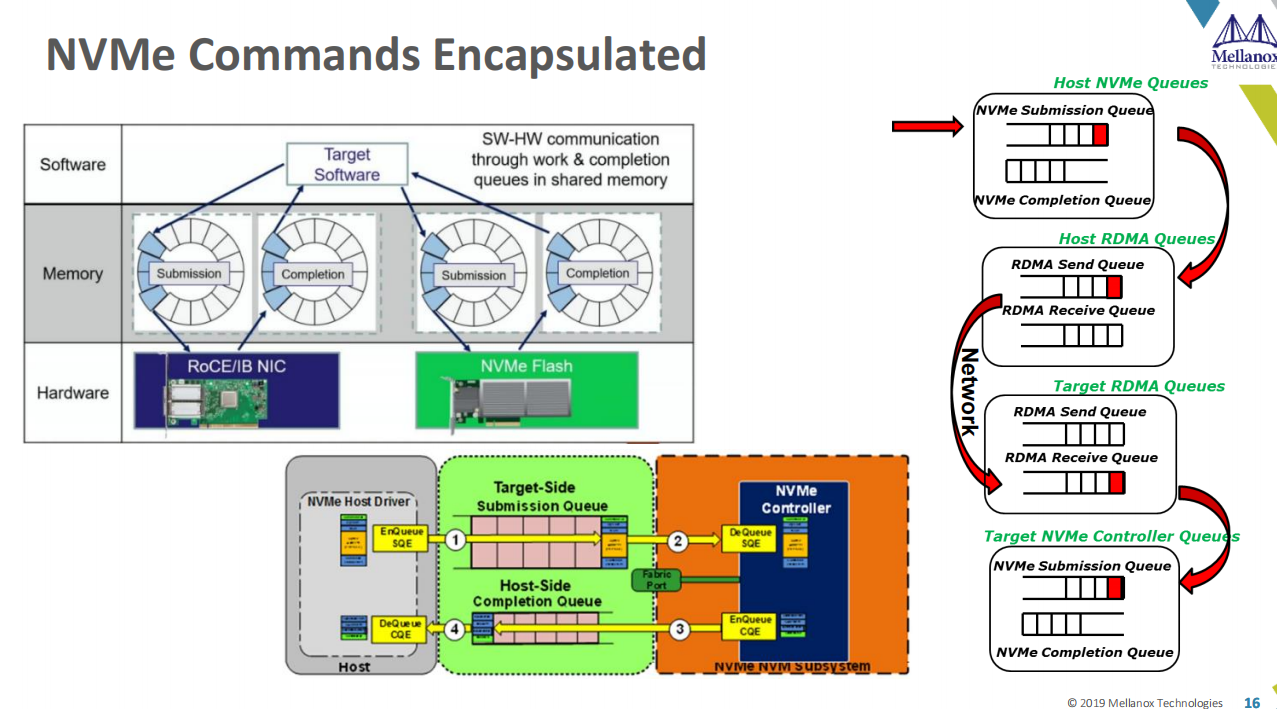
Target侧,打开来看如下图:
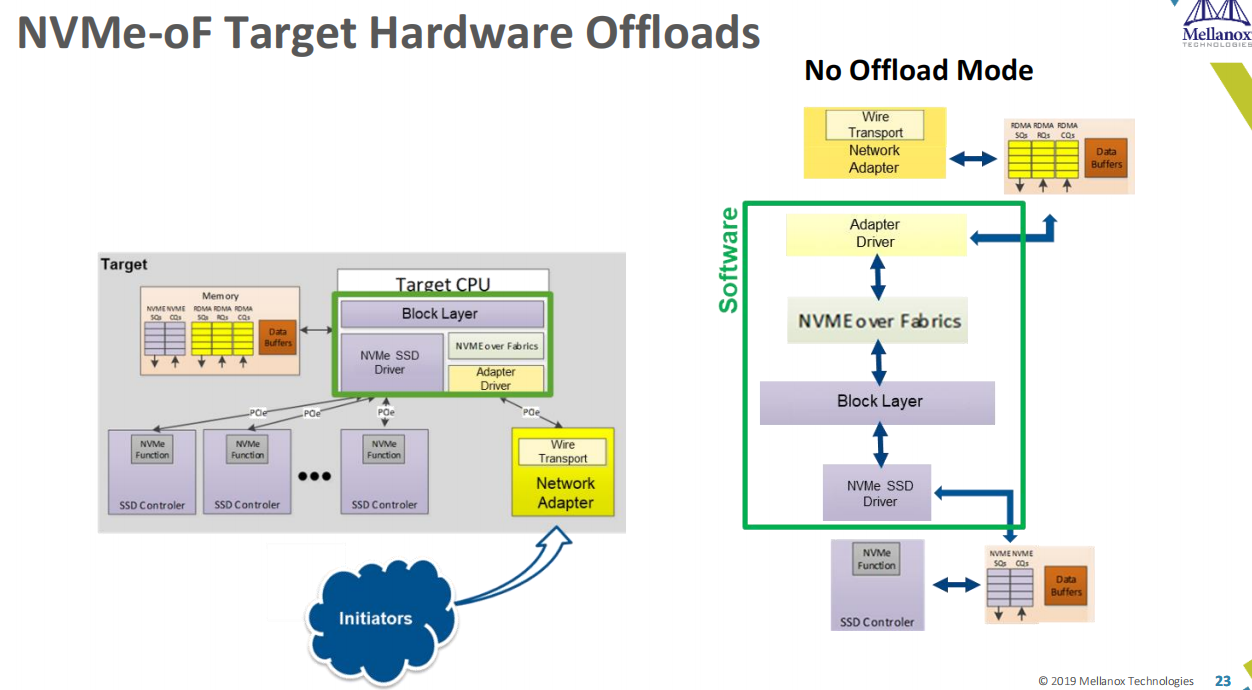
详细的流程如下:
host侧:
发包
//大部分代码在drivers/nvme/host/rdma.c
queue_rq
nvme_rdma_queue_rq
blk_mq_start_request
nvme_rdma_post_send
ib_post_send
收包
nvme_rdma_recv_done
nvme_rdma_process_nvme_rsp
blk_mq_rq_to_pdu
target侧:
初始化
//大部分代码在 drivers/nvme/target/rdma.c
nvmet_enable_port
nvmet_rdma_add_port
nvmet_rdma_enable_port
rdma_create_id(注册中断回调函数nvmet_rdma_cm_handler, 当RDMA HCA收到RDMA报文时调用)
收到控制面报文
nvmet_rdma_cm_handler
nvmet_rdma_queue_connect
收到数据报文
nvmet_rdma_recv_done
nvmet_rdma_handle_command
nvmet_req_init
nvmet_parse_io_cmd
nmve_cmd_read/nvme_cmd_write (分析命令,针对不同的后端,设置回调函数, nvmet_bdev_execute_rw)
nvmet_rdma_execute_command
req.execute(调用回调函数)
submit_bio
blk_mq_submit_bio
nvme_queue_rq(又回到本地的nvme host,调用nvme读写)a
nvmet_req_complete
nvmet_rdma_queue_response
ib_post_send(返回请求)
NVME Target Offload
观察上面的流程,会发现要回到block层绕一圈,于是MLX提出了直接访问NVME的优化机制,具体如下:
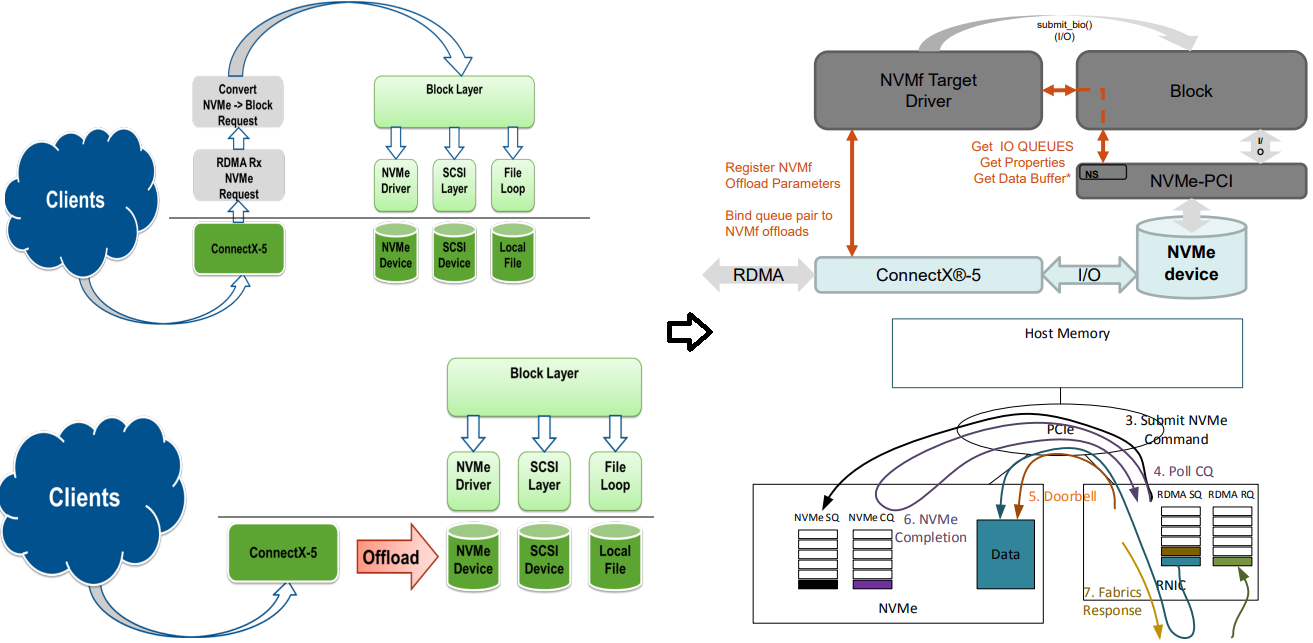
这个改动软件上主要是rdma-core的改动,控制面上创建好share queue,并把这个传递给硬件,kernel并不需要改动,
但是这个RFC并没有合入到rdma-core的主线,具体的RFC patch和实现可以参考下面几个链接:
libfabric
libfabric一般配合libibverbs(https://github.com/linux-rdma/rdma-core)使用。
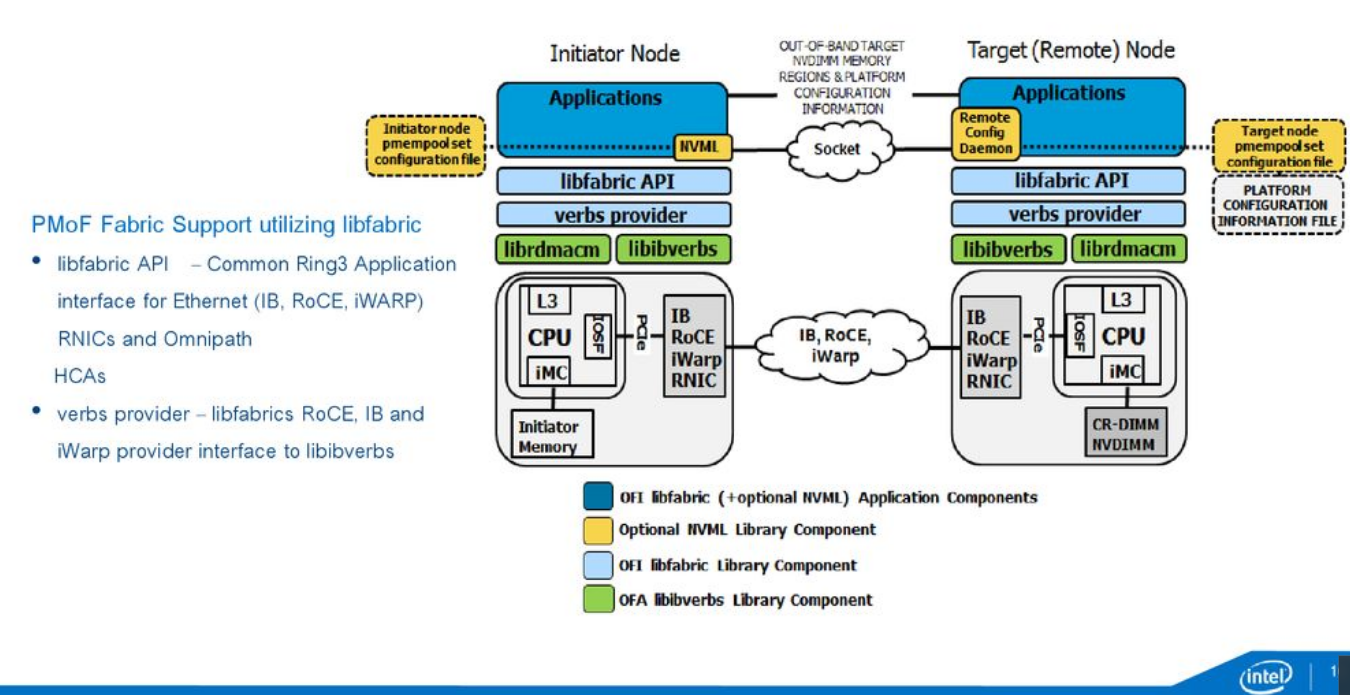
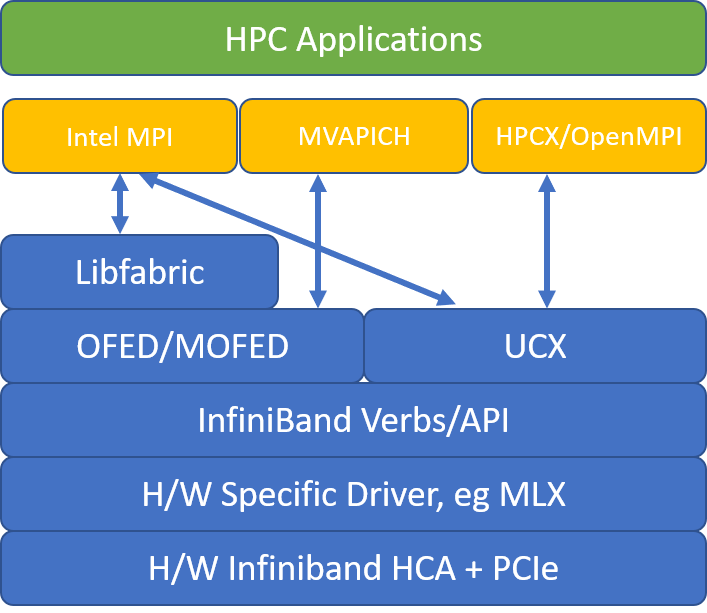
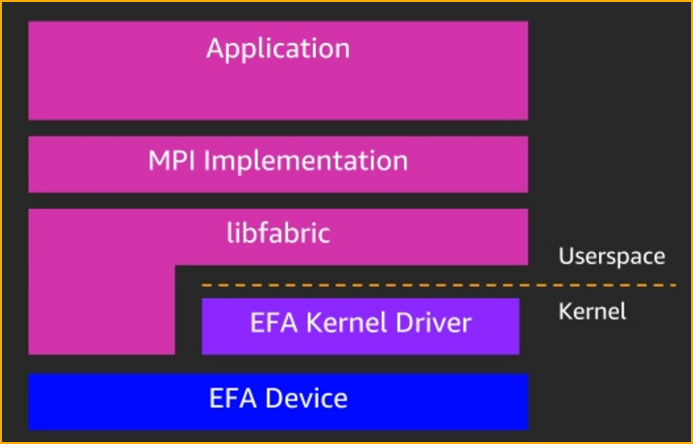
但亚马逊的Elastic Fabric Adapter用法不太一样,EFA直接在linux kernel实现了libfabric的provider驱动。
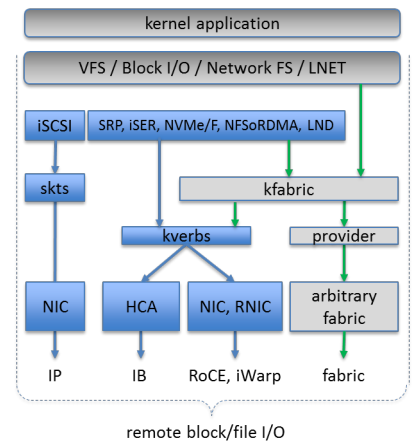
kfabric
在linux kernel,由于上层SRP、iSER、NVMe/F、NFSoRDMA要调用ib的verbs,而各个厂家的驱动层也要实现
类似的回调函数,OFED组织又做了一层抽象框架命名为kfabric,但是这个模块还一直没有何如到linux kernel主线,
最近的一次更新也是在16年了,可以认为已经停止开发了。
主要用于用LNET文件系统,可惜从linux kernel 4.18之后,lustre分布式文件系统被移除了内核,
但lustre官方仍在维护out of tree的代码,且由于ARM在hpc领域的绽放,linaro也在维护arm的版本,具体可以参考他们的官网。
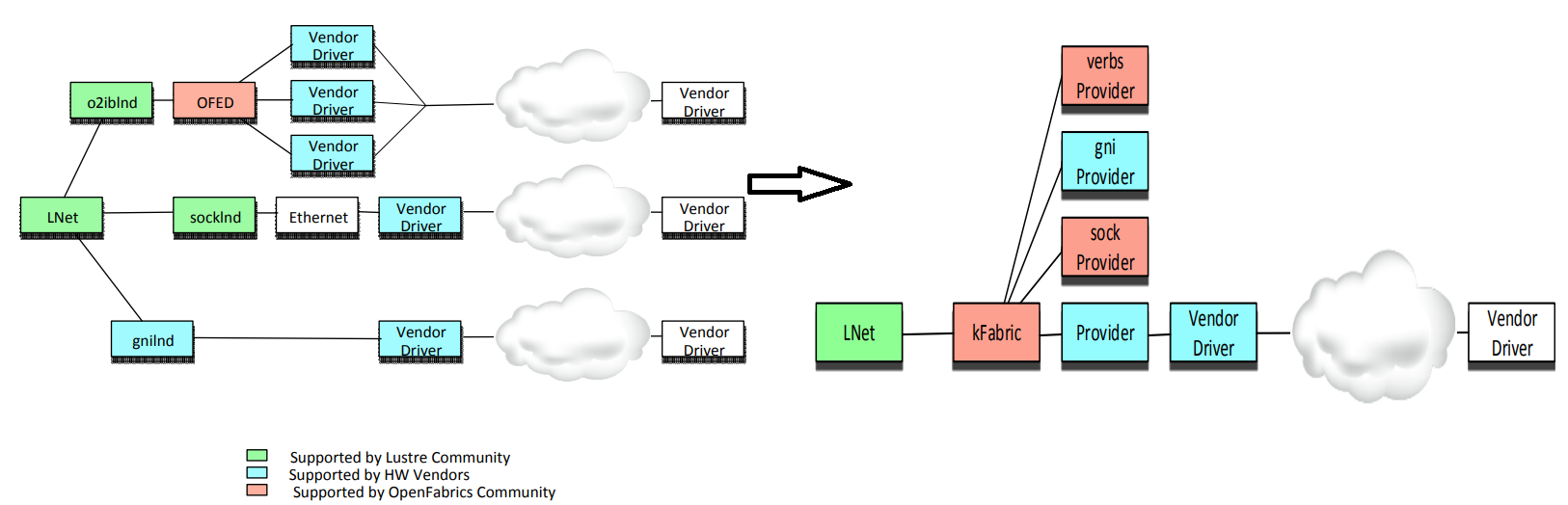
libfabric和kfabric
根据上节的介绍,其实libfabric和kfabric并不一定要配合使用,具体差异参考下图
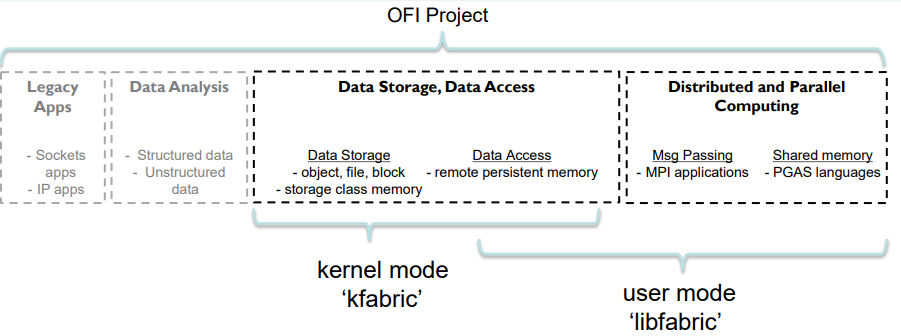
SMB
由于是windows上的技术,这里就不介绍了。
八卦
以前高端网卡基本都是intel和broadcom的市场,后面微软找MLX在数据中心合作,结果
MLX在25G时代一把上位。后面亚马逊又收购了同处于以色列的Annapuna Lab,做了自己的
RDMA,也就是后面的EFA(https://github.com/amzn/amzn-drivers)。
参考
- Storage Networking Industry Association
- Evolution of iSCSI
- Persistent Memory over Fabrics An Application-centric view
- Persistent Memory over Fabric Architecture Overview
- Set up Message Passing Interface for HPC
- Now Available – Elastic Fabric Adapter (EFA) for Tightly-Coupled HPC Workloads
- Pathfinding a Kernel Storage Fabric Mid-layer
- 云计算三大神器来了!CPU、GPU、DPU
- 深入理解Lustre文件系统-第3篇 LNET:Lustre网络
- lustre patchwork
- A triad-based architecture for a multipurpose Lustre filesystem at /rdlab
- NFS over SoftRoCE setup
- NFS/RDMA README
- NFS/RDMA Next Steps
- RDMA in Data Centers: Looking Back and Looking Forward
- The role of a InfiniBand and automated data tiering in achieving extreme storage performance
- NVIDIA MLNX_OFED Documentation Rev 5.3-1.0.5.0 Introduction
- iSER as accelerator for Software Defined Storage
- What is ISER?
- Mellanox Linux Driver Modules Relationship
- The OFED package
- Linux/iSCSI and a Generic Target Mode Storage Engine for Linux v2.6
- Performance Implications Libiscsi RDMA support
- How Ethernet RDMA Protocols iWARP and RoCE Support NVMe over Fabrics
- Ethernet Storage Fabrics: Using RDMA with Fast NVMe-oF Storage to Reduce latency and Improve Efficiency
- Linux iSCSI
- SCST-Usermode-Adaptation
- Storage Stack
- Linux Storage Stack Diagram
- Linux LIO 与 TCMU 用户空间透传
- LIO and the TCMU Userspace Passthrough
- tgt服务端流程分析
- tgt作者 FUJITA Tomonori个人主页
- Linux中三种SCSI target的介绍之各个target的优劣
- Creating an iSCSI Initiator
- Open-iSCSI
- Elasticsearch with Gluster Block Storage
- open-iscsi/scst 追踪一
- Add support for iSCSI Extensions for RDMA (ISER) target mode
- iser-target-rfc-v4
- TCMU学习笔记
- 中秱苏研-存储产品规划和实践经验分享
- TCM Userspace Design
- Ceph iscsi方案及环境搭建
- 一个iscsi target hung问题的解决过程
- NVMe over Fabrics - Demystified
- Accelerating Storage with RDMA
- Using RDMA with Fast NVMe-oF Storage to Reduce latency and Improve Efficiency
- SPDK/NVMe存储技术分析001 - SPDK/NVMe概述
- NVMe Over Fabrics Support in Linux
- RDMA杂谈 专栏索引
- How to setup NVMe/TCP with NVME-oF using KVM and QEMU
- Deep Dive into NVMe™ and NVMe™ over Fabrics
- NVMe over Fabrics Target
- NFS Over RDMA Community Development
- Using Tracepoints to Debug iSCSI
- NVMe over TCP
- Block - 1 Base

