MESA3D编译架构
整个架构如下
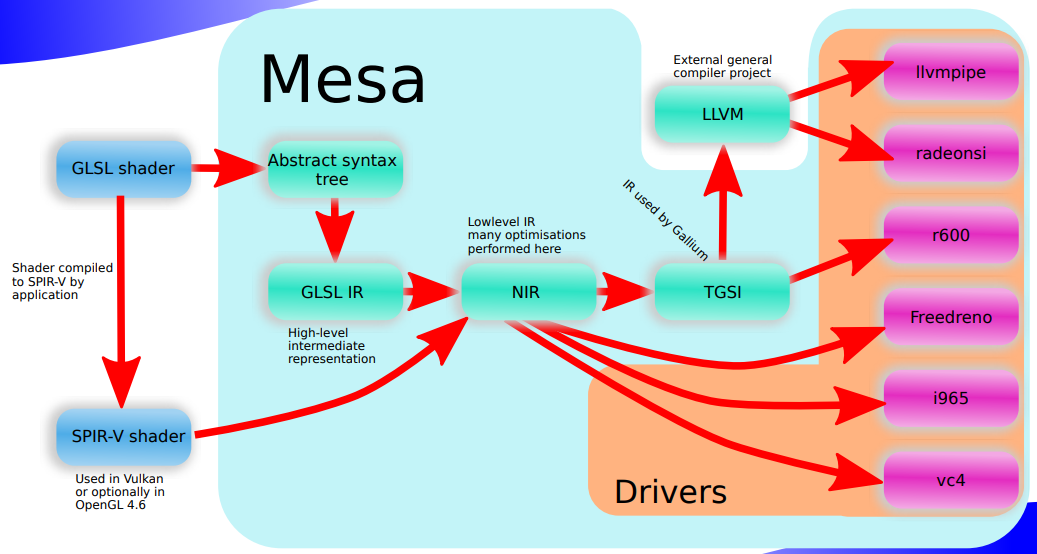
如果是Vulkan,shader从SPIRV先编译成NIR,再编译成native。
如果是OpenGL,则从GLSL先编译成NIR,再编译成native。
上图中TGSI基本已经不用,除了在virgl里面还用之外,基本都已经切换到LLVM或者厂家的自研编译器中。
GLSL转换成GLSL IR
GLSL的shader的处理入口在_mesa_glsl_compile_shader中,shader的源码首先经过词法分析src/compiler/glsl_lexer.ll和
语法分析glsl_parser.yy的通用Lex/Yacc处理,输出抽象语法树(AST),在经过ast_to_hir.cpp处理,转成GLSL IR。
GLSL IR处理
GLSL IR在ir.h中定义了几个重要的类,一般分成指令类,条件控制类和函数类。
exec_node,基础类,作为最小的执行单元,包含前后指针,分别指向之前和之后的指令。ir_insturction,所有指令的基础类ir_rvalue,右侧赋值类,是表达式的几率ir_expression,表达式ir_texture,纹理ir_swizzle,向量或者矩阵变换类ir_dereference,用于访问存在在变量、数组和数据结构中的值ir_constant,常所有基本类型的常量ir_variable,变量ir_loop,循环ir_if,条件控制
GLSL的IR调试一般通过MESA_GLSL=dump,比如 MESA_GLSL=dump glmark2。
GLSL IR lower处理
lower处理都在src/glsl/lower_*.cpp文件中,主要作用是重写部分生成的IR。这个过程主要的动作就是遍历IR树,对于所有
叶子节点一般都有visit函数,非叶子节点都有vist_enter和visti_leave函数。
以lower_instructions.cpp为例,一般的优化过程都是用效率高的IR代替生成的IR。
GLSL IR转换成NIR
这部分的处理在st_link_nir和glsl_to_nir中处理。之后通过st_nir_opts做lower的优化。
AMD指令转换流程
NIR -> LLVM -> AMD GPU IR
AMD直接修改了LLVM源码,具体参考LLVM AMD GPU改动
ARM Midgard/Bifrost转换流程
NIR -> BIR
MESA编译过程中会生成bi_builder.h,其中会定义从NIR到BIR指令的映射关系。代码流程如下:
bifrost_compile_shader_nir
emit_cf_list
emit_block
bi_emit_instr
bi_emit_alu
bi_fma_to
为什么不直接编译成native ISA呢?
NIR的处理积累了大量经验,包含SSA处理,控制流处理。
编译优化在后端还是NIR?
答案是NIR。
2019年XDC上intel专家Jason Ekstrand特意强调intel花了4年时间把backend的优化又搬到NIR中来。
调试方法
- 参考mesa 环境变量, 比如加上
NIR_PRINT=1可以导出NIR到SSA的转换过程;
加上”AMD_DEBUG=vs”,可以导出NIR到SSA,以及LLVM优化的过程。
编译性能优化
- 最直观,看帧率和效果
- 执行shader-db看看前后优化结果
- 通过perf抓shader-db编译热点函数,修改对比。
编译优化趋势
2019年ACO(AMD compiler)被运营Steam的公司Valve(CS开发公司)提出来后,现在已经合入到MESA主线中,当前只支持AMD GPU。
Intel也提出IBC(intel backend-compiler)的概念。
优化的维度主要从时间和帧率考虑,使用的测试脚本可以看参考连接。
参考
- A TRIP DOWN THE GPU COMPILER PIPELINE
- Embedded Graphics Drivers in Mesa
- How to not write a back-end compiler
- NIR: A new compiler IR for Mesa
- A year of ACO
- Optimizing shader assembly instruction on Mesa using shader-db
- Optimizing shader assembly instruction on Mesa using shader-db (II)
- 火焰图:全局视野的Linux性能剖析
- An introduction to Mesa’s GLSL compiler (I)
- The Valve-funded shader compiler ‘ACO’ is being queued up for inclusion in Mesa directly (updated: merged)
- ACO: A New Compiler Backend for RADV
- Implementing Optimizations in NIR
- Lessons_from_Control_Flow_in_AMDGPU
- Optimizing i965 for the Future
- SHADERS IN RADEONSI DYNAMIC LINKING AND NIR IN RADEONSI DYNAMIC LINKING AND NIR
- TGSI for Mesa
- NIR introduction
- GLSL compiler: Where we’ve been and where we’re going (2015 Edition)
- NIR on the Mesa i965 backend End

