前言
为了解决系统不工作时的功耗消耗,linux提供了休眠(suspend to ram or disk)、关机(power off)、复位(reboot)。
为了解决运行时不必要的功耗消耗,linux提供了runtime pm、cpu/device dvfs、cpu hotplug、cpu idle、clock gate、power gate、reset等电源管理的机制。
为了解决运行时电源管理对性能的影响,linux提供了pm qos的功能,用于平衡性能与功耗,这样既能降低功耗,又不影响性能。
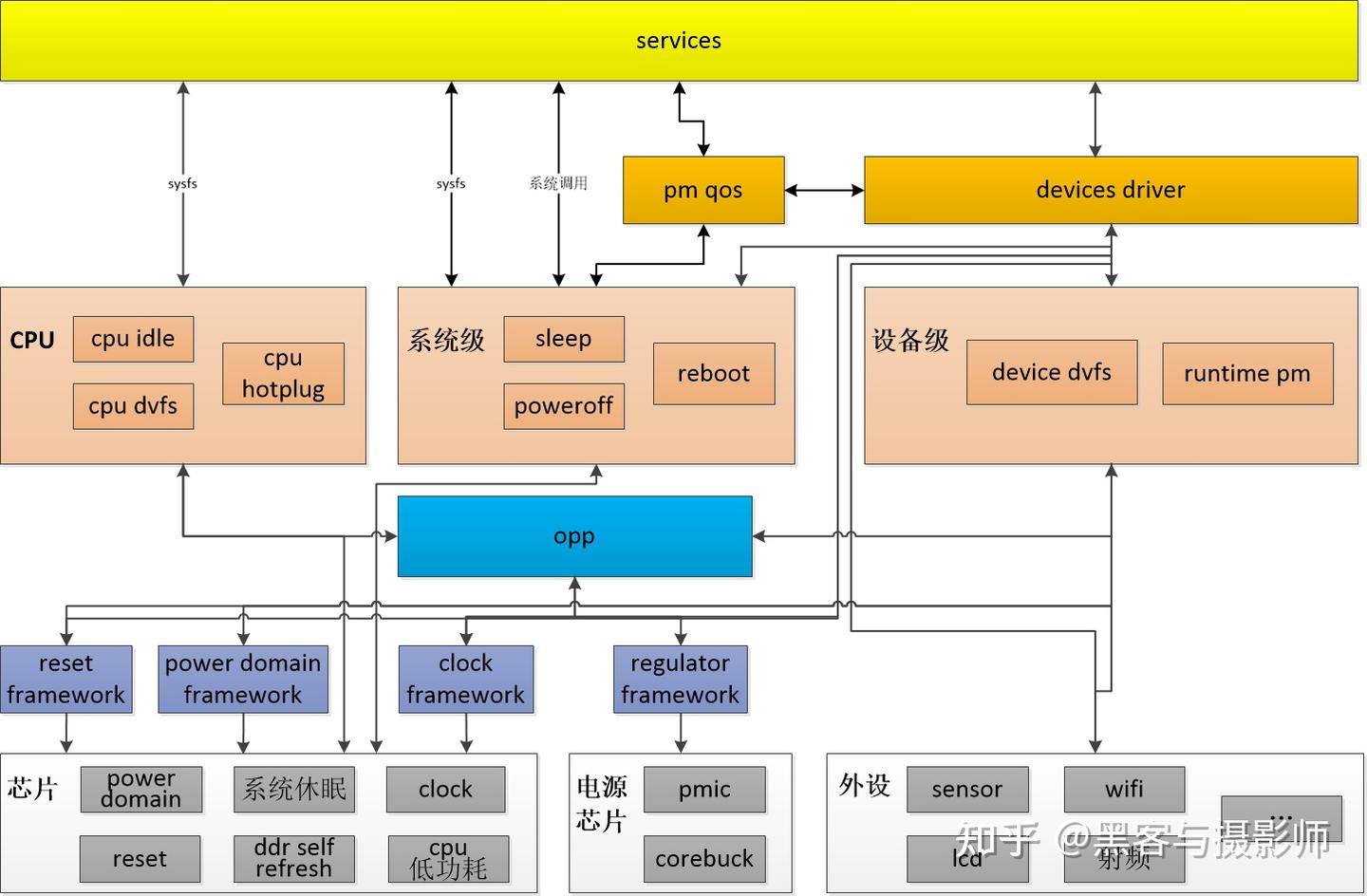
芯片上通过电源域、电压域和时钟域,以及pmic和各种sensor来配套支持功耗控制。
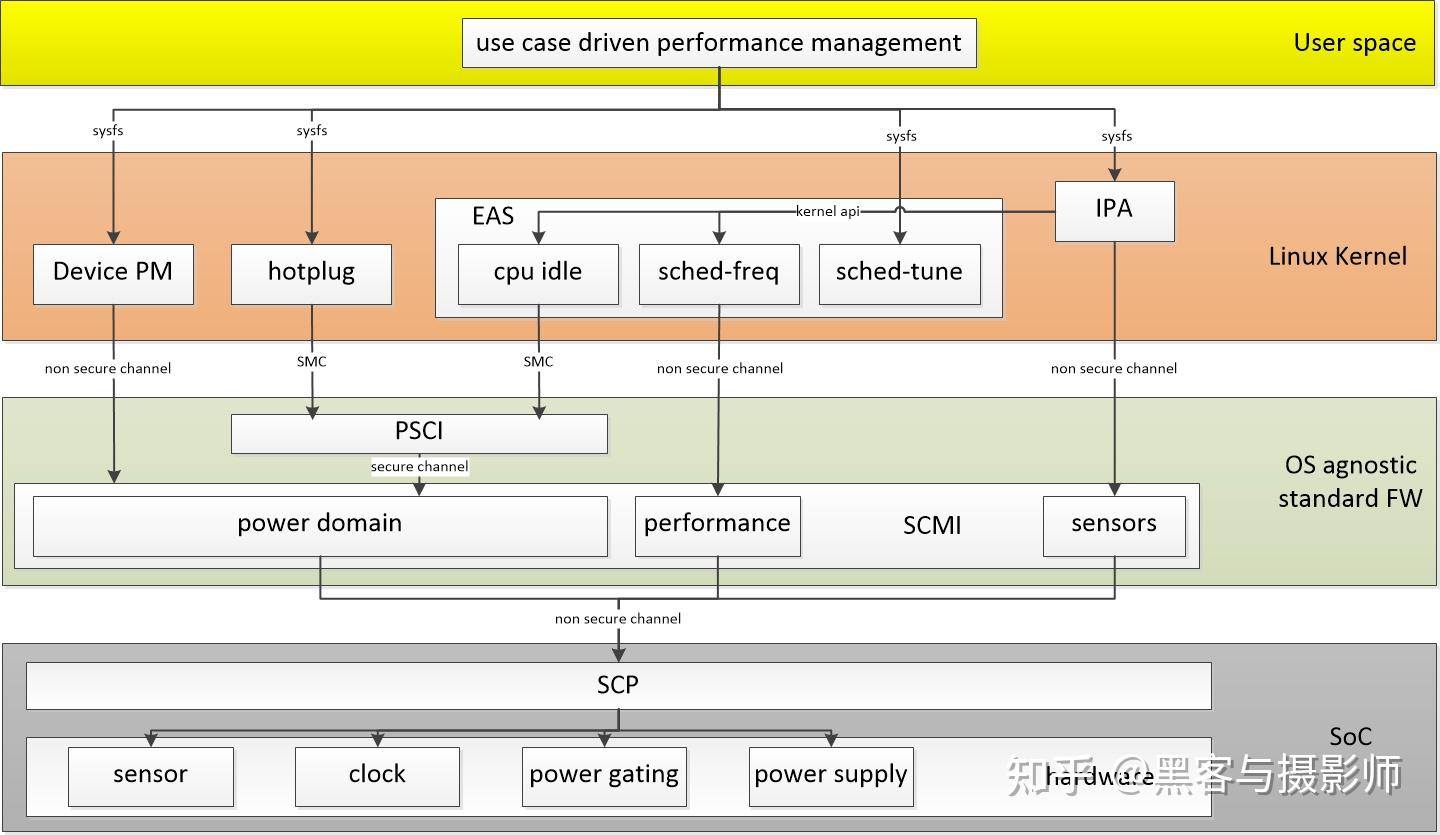
在ARM64 SoC上主要通过SCMI接口调用SCP功耗协处理器控制功耗。
linux kernel中发起的操作,会经过电源状态协调接口(Power State Coordination Interface,简称PSCI),
由操作系统无关的ATF(ARM Trusted Firmware)做相关的处理后,通过系统控制与管理接口SCMI(System Control and Management Interface),
向系统控制处理器SCP(system control processor)发起低功耗操作。
SCP最终会控制芯片上的sensor、clock、power domain、及板级的pmic做低功耗相关的处理。
EAS面向功耗优化的调度
为了更好的在运行时省功耗,EAS(Energe Aware Scheduling)调度被引入了linux kernel,详细参考EAS patch 链接。
EAS必须配合“schedutil” governor一起使用。
CFS(Completely Fair Scheduler)是linux kernel的默认调度器,但是在使用中发现CFS如下几个问题:
- CFS主要是为了服务器性能优先场景而设计的,主要目标是最大限度地提高系统的吞吐量,CFS调度的目标是所有任务都平均分配到系统所有可用的CPU上。
- CFS主要针对SMP系统,对于非SMP系统支持不足,比如说arm.big.little架构以及intel PE核架构。
- 没有充分利用各个核的功耗,性能,频率差异来达到性能和功耗的最优平衡。
- CFS使用PELT(per entity load tracking)跟踪任务负载,存在前摇和后摇时间,比如一个网络进程睡眠了500ms,然后突然突然发送或者接收大量网络数据包,PTLT并不能马上识别出它是一个重活。
为了弥补CFS的缺点,EAS引入了能量模型概念,EAS试图统一内核的cpuidle, cpufreq和调度三个不同核心部分,它们之前都相互独立,能量模型有助于统一它们,皆可能节省功耗提高性能。
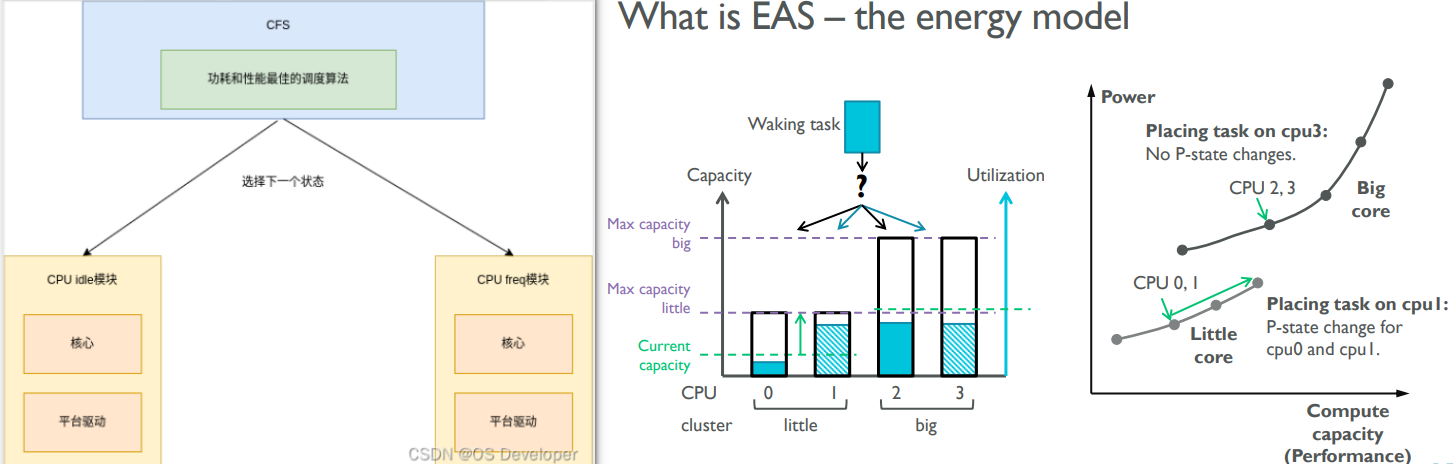
再调度时,EAS从runq选取任务时,会从能效考虑从一个idle的core跑,或者调频放到一个有负载的core上。
不仅如此,EAS还将进程/程序/应用分为四个cgroup,即 top-app, system-background, foreground, and background。
EAS关键结构体:
em_cap_state {
unsigned long frequency; /* cpu的频率 */
unsigned long power; /* 改频率下的功耗 */
unsigned long cost; /* 能效系数 */
}
EAS中WALT(Windows-Assist Load Tracing)算法调度策略大致如下:
- 一个系统中cpu的最高计算能力被量化成1024,小核CPU的最高计算能力也要量化,如512.
- 要判断一个就绪队列的当前实际计算能力有多少,采用实际算力,读取
cfs_rq->avg.util_avg可得到CFS就绪队列的实际算力。 - 要计算一个进程p的实际算力,我们采用
p->se.avg.util_avg。 - 需要在小核性能域以及大河性能域里面对每个cpu进行计算。假设把进程p添加到该cpu里,是否能够容下?不能超过处理器额定算力的80%。
- 要看大、小和这两个性能域里面,哪个cpu最适合安放,也就是说,容纳了进程p之后,它的剩余的计算能力最多的为候选者。如小何CPU1和大核CPU3位候选者。
- 比较进程运行在CPU1或者CPU3上最省电,经过发现最终迁移到CPU1上最省电,就选择CPU1。
其它
如果不想让linux接管功耗的话,可以通过ACPI的CPPC接口cppc_set_auto_sel,让固件控制。

