引子
几年前看到Dougall Johnson写的M1 Apple芯片微架构的材料,就一直想模仿,但是一直没有挤出时间来。
背景
本文讲的芯片微架构主要是指流水线(pipeline),现在芯片pipeline一般会有几个stage,通常包括fetch, decode, execute和commit,如下图所示:
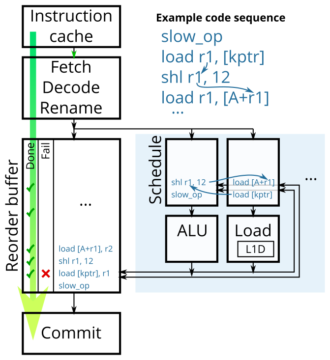
整个软件执行起来似乎如绿色箭头一样是顺序执行的,但现代处理器为了提升指令执行并发度,其实decode和commit之间是乱序执行的(out of order)。
decode后,会把指令顺序的放到reorder buffer中,告诉执行单元尽快干活,干完之后通知reorder buffer这个活干完了。之后由commit单元按照入对顺序把执行完的指令捞出来出队。
如果再把front end, back end,预取等概念加进来的话,更类似于下面这个图。
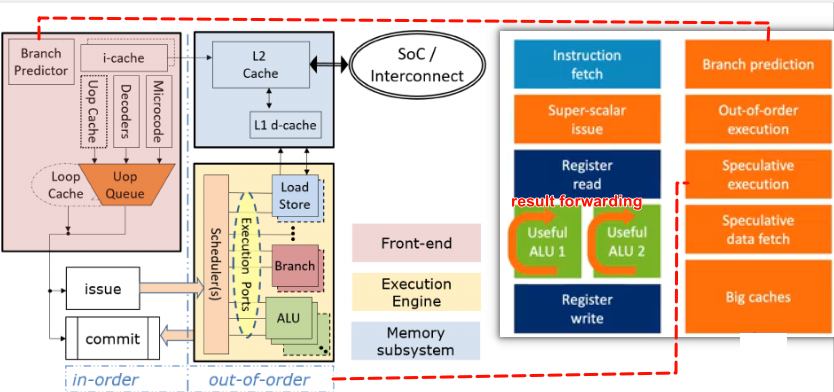
指令在执行过程中,会拆分成更小的单元macro-ops(mops decode单元)和micro-ops(uops dispatch单元),能拆分成多少个也叫width,或者说解码宽度(pipeline width)。
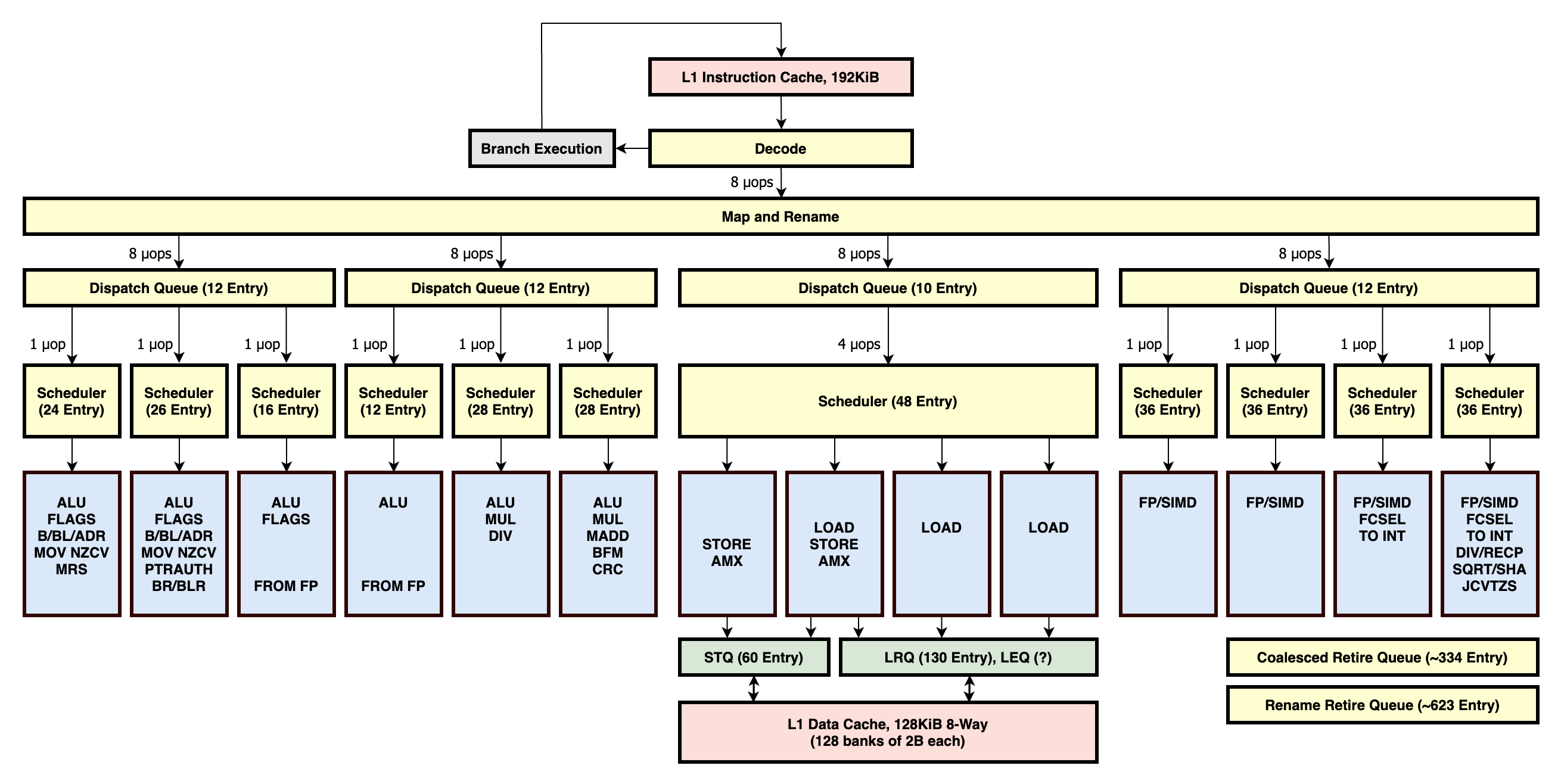
下图是ARM Neoverse V1的微架构,可以观察到每个单元的width,有多少个EU(执行单元)

再来一个苹果M1的对比:
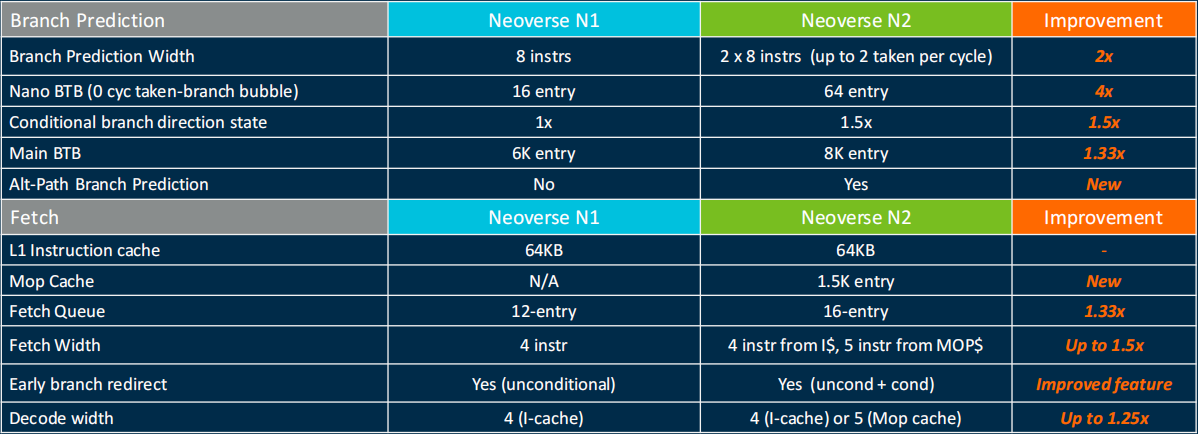
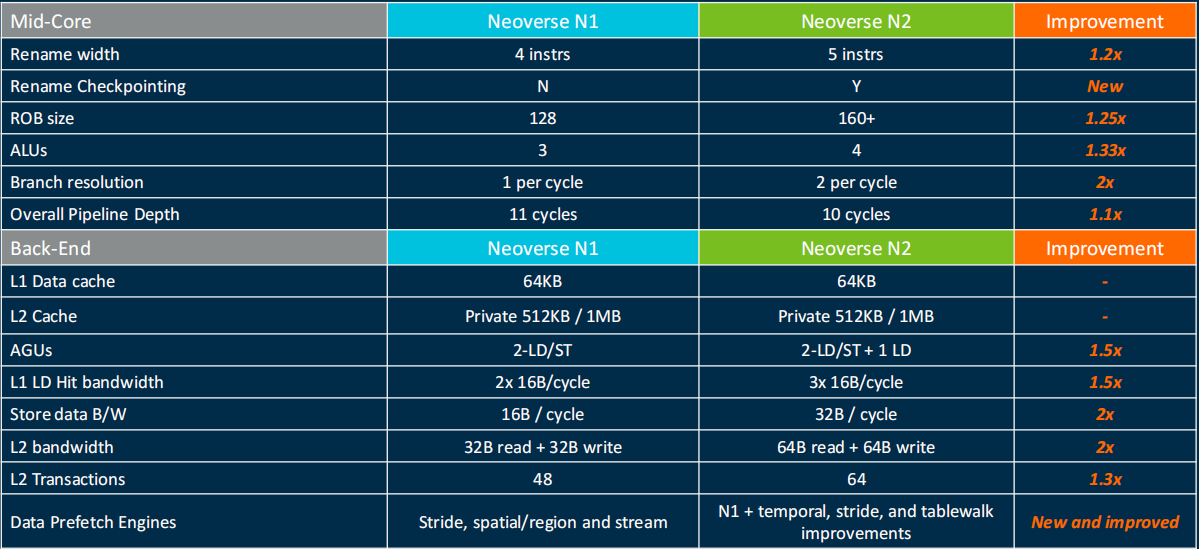
这里再放一个ARM N1到N2的微架构演进的列表:
范围
本文软件探测的范围实际上就是想覆盖上图中所有的单元,包括各个Cache,ROB大小,EUs种类个数,LSU个数。
所有代码可以参考 我的工具箱。
Cache探测
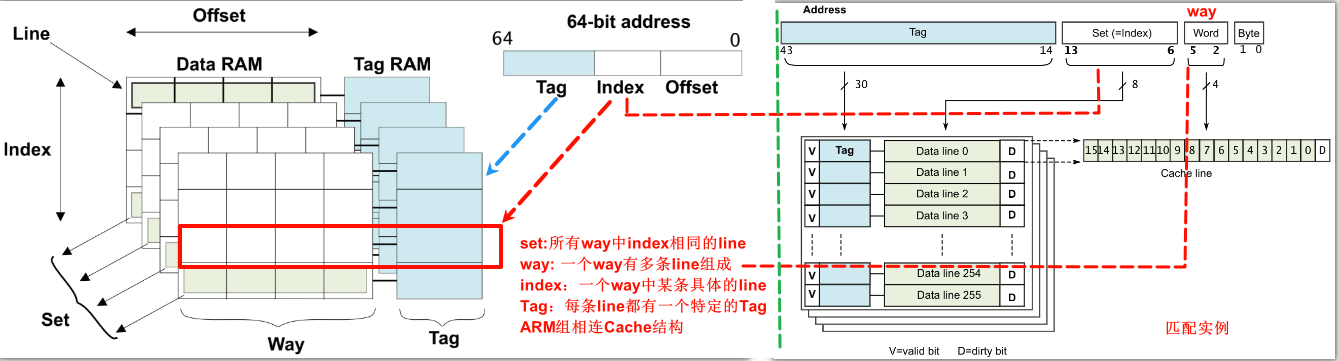
探测之前,先科普下ARM上Cache的组织方式,具体如下图:
Cache探测除了组织方式以外,还包括时延和带宽,主要通过pointer chase这种算法,大部分主流的内存测试套比如lmbench均基于该算法。
算法的基本思想是创建一个数组,每个数组元素中保存一个指针,指向下一个要访问的数组元素,设置不同的步长,来遍历这个数组,观察时延的变化。
一般L1 Cache都是个位数的Cycle,L2 Cache大概十几个Cycle,L3 Cache大概50以内个Cycle左右,DDR基本都是上百个Cycle。
于是呢一旦时延变化较大,则肯定发生cache miss,就可以判断cache的大小了。
Cache Coherence的机制和实现可以参考卡内基梅隆大学的Snooping-Based Cache Coherence
Cache影响
Cache对软件的影响,主要有cache miss,false sharing(多core同时访问同一个cache line),cache thrashing(多core同时访问不同way的同一个index的cache line,也就是set冲突)。
更多有趣的cache影响软件行为,可以参考陈浩的这篇文章与程序员相关的CPU缓存知识
执行单元个数
主要看不同种类指令的吞吐率,可以参考uarch bench,也就是参考链接中的第一篇文章。
ROB大小
主要参考Henry Wang的测试ROB大小的文章,也放在参考链接中了。
通过填充NOP指令在两次cache miss的load中,来观察执行时间的变化,由于nop指令执行时间非常短,一旦时间变化很大,那么可以判断第二次cache miss的指令在ROB队列以外了。
代码实现可以参考microarchitecturometer的实现。
总结
最后放一张为了提升性能的总版图:
参考
- Performance Speed Limits
- uarch bench wiki
- The Microarchitecture Behind Meltdown
- x86, x64 Instruction Latency, Memory Latency and CPUID dumps
- realworldtech and its forum
- uops info
- The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers
- Intel Core Microarchitecture Pipeline
- CPU Introspection: Intel Load Port Snooping
- AmpereOne at Hot Chips 2024: Maximizing Density
- computer microarchitecture之out-of-order execution
- Apple Microarchitecture Research by Dougall Johnson
- Measuring Reorder Buffer Capacity
- Memory Performance in a Nutshell
- Finding Your Memory Access Performance Bottlenecks
- computer architecture - microarchitectural channels
- performance tools
- The Validation Buffer Microarchitecture for Multithreaded Processor
- Neoverse V1 - Microarchitectures - ARM
- 移动芯片排行
- Arm’s New Cortex-A78 and Cortex-X1
- Apple M1
- ARM processor
- RPi 4 tuning: The code
- 《计算机体系结构:量化研究方法》 第1章 量化设计和分析的基础知识(一)
- Computer Architecture Research with RISC-V - SonicBOOM: The 3rd Generation Berkeley Out-of-Order Machine
- 如何设计一个成功的指令集架构
- Arm Mali GPU Training Series Ep 1.4 Hardware shader cores
- A Metric-Guided Method for Discovering Impactful Features and Architectural Insights for Skylake-Based Processors
- Understanding CPU Microarchitecture to Increase Performance
- Zen 5’s Leaked Slides
- Lecture 7 (2-1-05) Superpipelining and Superscalar Architecture Overheads
- DRILLING DOWN INTO THE XEON SKYLAKE ARCHITECTURE
- Customizing Processors
- A Journey Through the CPU Pipeline
- Memory Barriers: a Hardware View for Software Hackers
- Cache: a place for concealment and safekeeping
- 17_ARMv8_高速缓存(二)ARM cache设计
- 从技术角度聊CPU分支预测器
- 卡内基梅隆大学的Parallel Computer Architecture and Programming, Spring 2024
- Cache snoop
- The microarchitecture of Intel, AMD and VIA CPUs: An optimization guide for assembly programmers and compiler makers
- Intel 海光 鲲鹏920 飞腾2500 CPU性能对比

