nvidia gpu内存管理架构演进
先看个大图,回忆下nvida GPU架构演进过程中,内存管理相关的演进
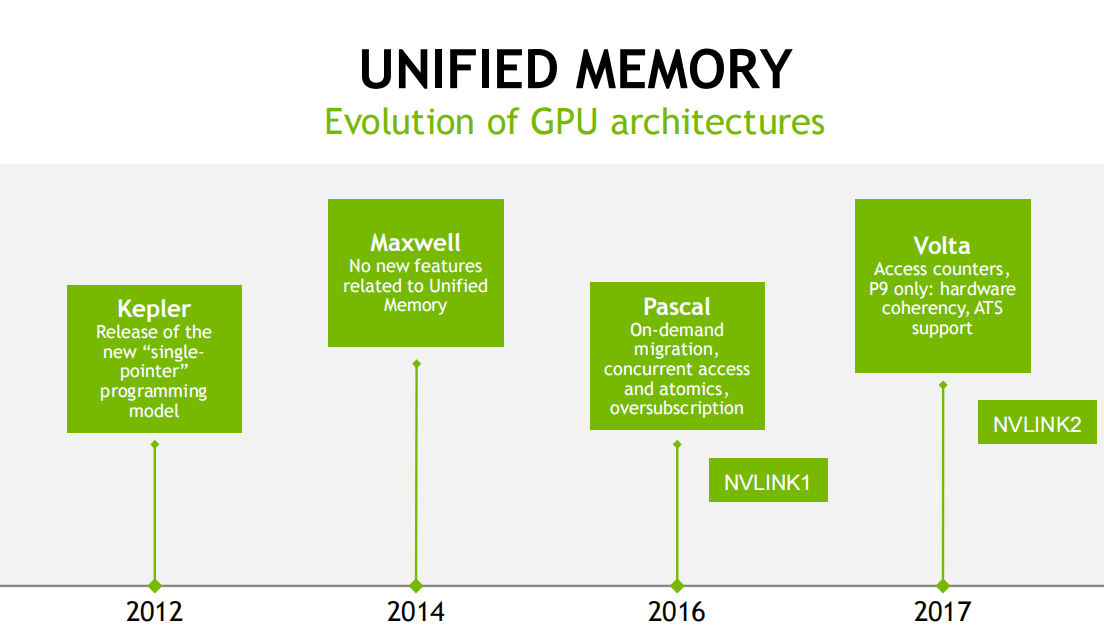
借用下星辰变境界演进的说法。
星云期
最早的时候很简单,只是为了让用户态可以访问GPU的显存,于是gpu驱动就在linux kernel中创建了一个设备,
提供ioctl alloc和mmap操作,用户调用cudamalloc的时候,通过传入该设备的fd,触发设备的alloc和mmap操作,
通过remap_pfn_range函数把GPU可访问的物理地址转换成用户态可以访问的va。
通常的写法如下:
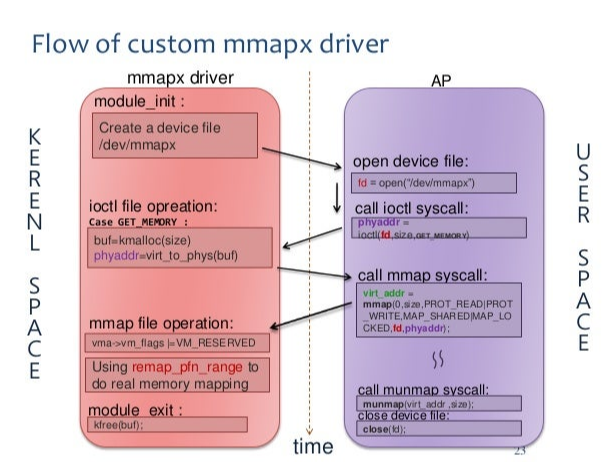
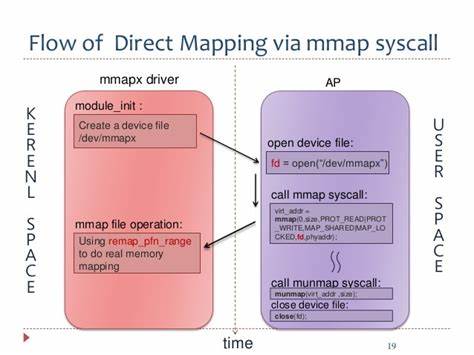
这种做法在当前的MESA/DRM中很常见,这里放下AMD GPU的代码,实现很类似:
放在cuda上,用户态的写法如下:

内核态中的代码也很清晰,基本都是在uvm.c中,具体流程如下:
uvm_mmap_entry
uvm_mmap
uvm_vma_wrapper_alloc
uvm_va_range_create_mmap

